Conforme explicitado no capítulo de introdução, um projeto de ativo digital na plataforma pode ser composto por diversos softwares desacoplados. Assim, cada um destes softwares-componentes será uma aplicação independente no projeto, com seu código-fonte armazenado e versionado em um repositório específico no GitLab e tendo um ciclo de vida próprio.
Existem duas formas de se criar uma aplicação em um projeto no Embrapa I/O:
1. A partir de um boilerplate
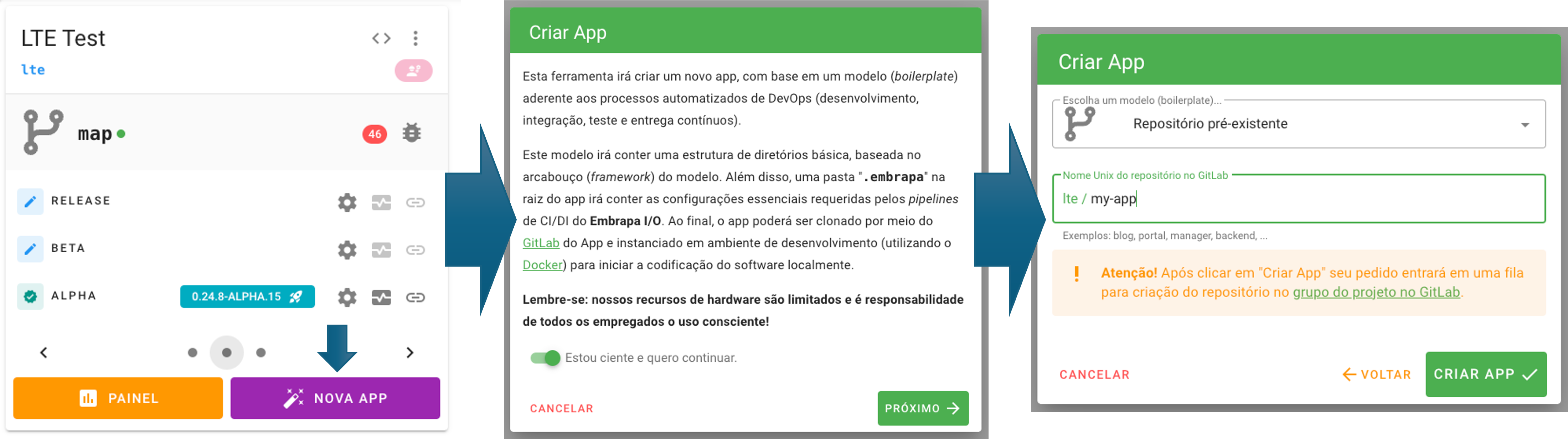
Para criar uma nova aplicação a partir de um boilerplate, um arquiteto da solução do projeto deverá clicar no botão “Nova App”, no rodapé do card do projeto. Isso iniciará um wizard que guiará o usuário por alguns passos. Inicialmente é apresentado ao usuário um disclaimer, o qual ele deverá estar ciente.
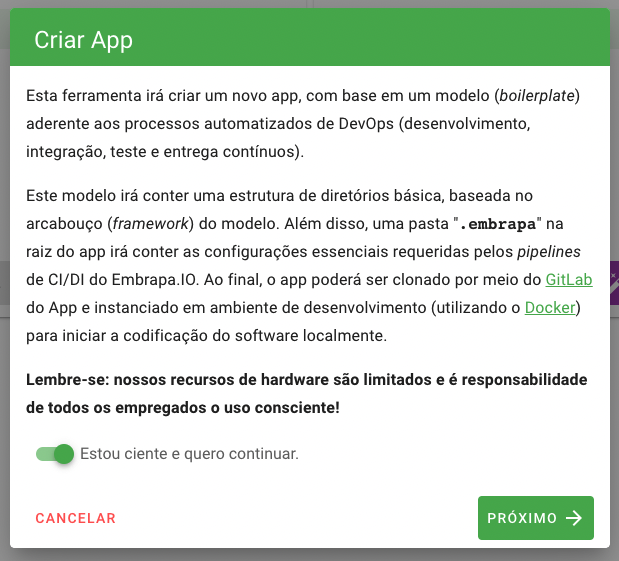
No segundo passo, o usuário deverá selecionar o boilerplate que será utilizado para gerar o código-fonte inicial da aplicação. Conforme foi explicado no capítulo de introdução, o boilerplate é necessário para estruturar a aplicação no padrão requerido pelo Embrapa I/O. Na maioria das vezes o boilerplate será apenas uma espécie de Hello Word, ou seja, o menor conjunto de código-fonte possível para instanciar uma aplicação em determinada linguagem de programação ou framework de desenvolvimento, porém estruturado com os requisitos para torná-lo aderente aos pipelines de DevOps do Embrapa I/O.
É possível criar uma aplicação sem utilizar um boilerplate como base. Para isso deverá ser utilizada a opção “repositório pré-existente” no campo de seleção. Neste caso, o repositório da aplicação deverá ser criado de antemão e possuir a mesma estrutura requerida por um boilerplate, conforme explicado no tutorial de criação de boilerplates.
Ao selecionar o boilerplate serão apresentadas informações sobre ele, tal como links de referência e a sua equipe mantenedora. Qualquer usuário da plataforma pode propor um novo boilerplate, colaborando com a comunidade Embrapa I/O.
Neste passo o usuário deverá também selecionar um nome unix para a aplicação (somente letras minúsculas, números e hífen). A combinação com o nome unix do projeto (namespace) deverá ser única em toda a plataforma. Por exemplo, na imagem abaixo está sendo definido como pwa o nome unix da aplicação, sendo que o nome final com o namespace será pasto-certo/pwa. Caso esteja criando uma aplicação sem o boilerplate, o nome unix deverá ser o mesmo do repositório criado previamente.
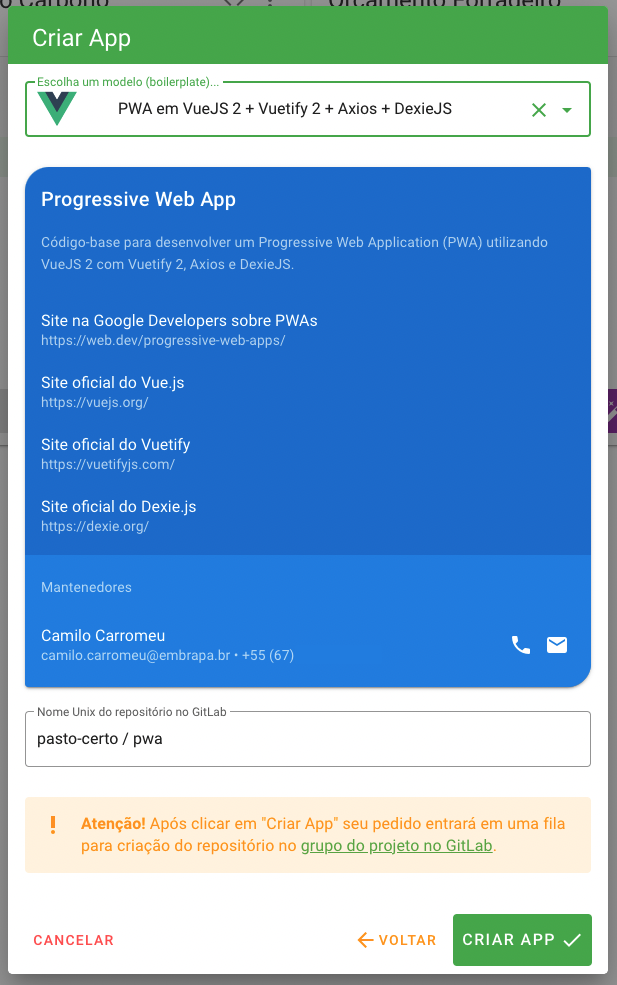
Ao clicar no botão “Criar App” a plataforma irá colocar a requisição em uma fila para o autômato Genesis, de provisionamento de entidades. O autômato fará um fork do repositório do boilerplate para o projeto, customizando alguns detalhes neste processo.

No card do projeto na dashboard fica disponível a lista de todas as aplicações naquele projeto. Para cada aplicação nesta lista, é possível configurar a build, ou seja, os estágios de maturidade que podem ser disponibilizados publicamente: alpha (testes internos), beta (testes externos) e release (produção).
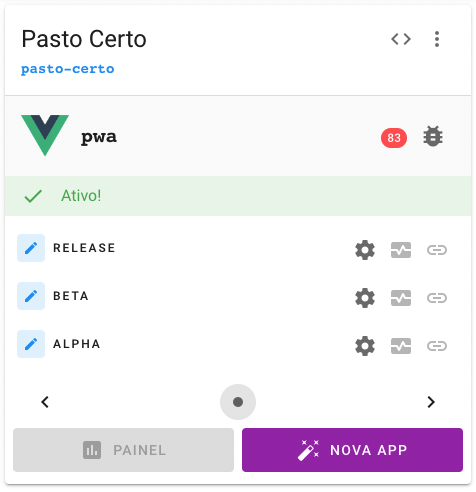
Por fim, o repositório da aplicação estará disponível no grupo do projeto no GitLab. A equipe de desenvolvedores poderá agora iniciar o planejamento do desenvolvimento e realizar o clone do código-fonte para o ambiente local de desenvolvimento, codificar a aplicação conforme os requisitos, seguindo boas práticas de desenvolvimento, e fazer o commit e push de volta ao repositório. Adicionalmente, a equipe pode contar com uma ferramenta para monitoramento de erros (error tracking).
2. A partir de um repositório GIT
Quando a aplicação é criada a partir de um boilerplate existe o grande benefício desta já nascer inerentemente conteinerizada, integrada às ferramentas de monitoramento (Matomo, Sentry, SonarQube, etc) e aderente aos pipelines de deploy de aplicações da plataforma. Entretanto, exitem situações em que a criação da aplicação a partir de um boilerplate não será adequada. Os casos mais comuns são:
- quando não há no catálogo de boilerplates algum que atenda às especificações tecnológicas definidas para a aplicação; e
- quando se trata de uma aplicação existente que está sendo migrada para a plataforma Embrapa I/O.
Nestes casos, a equipe de desenvolvimento precisará adequar o código-fonte da aplicação para que esta seja reconhecida pela plataforma, devidamente monitorada e aderente aos processos de DevOps.
Atenção! Caso as especificações técnicas do ativo que será desenvolvido não estejam contempladas em nenhum boilerplate do catálogo, é fortemente recomendado avaliar se, ainda assim, não existe algum boilerplate que possa ser “ajustado” para contemplá-las. Muitas vezes pode ser mais fácil e rápido efetuar estes ajustes do que partir do “zero”, tendo que efetuar todos os passos (que serão vistos logo mais) de adequação para tornar o código-fonte aderente à plataforma Embrapa I/O.
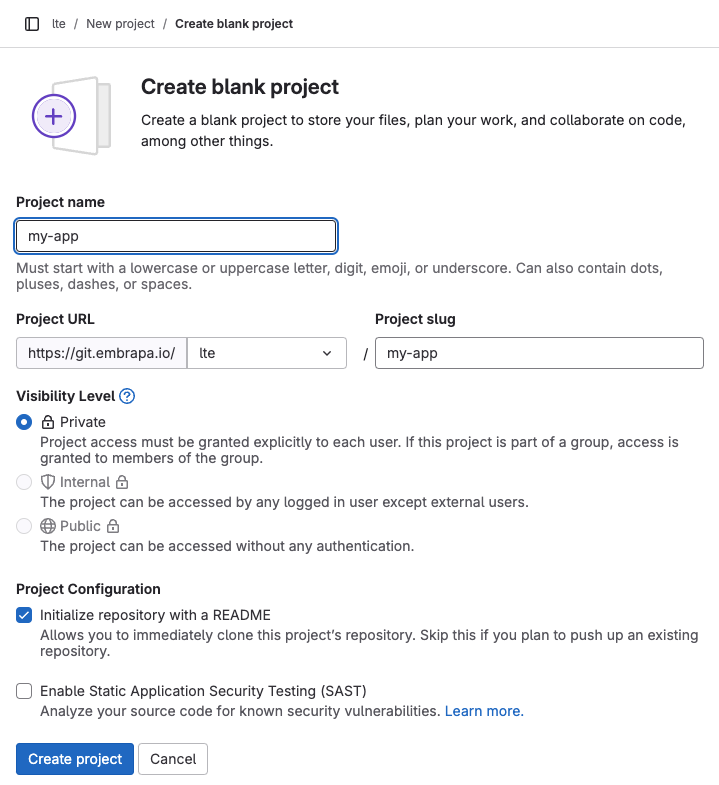
Para iniciar, será preciso primeiramente criar o repositório GIT. Para isso, um arquiteto de solução do projeto deverá acessar o GitLab da plataforma, navegar até o grupo de repositórios do projeto e criar manualmente um novo repositório:
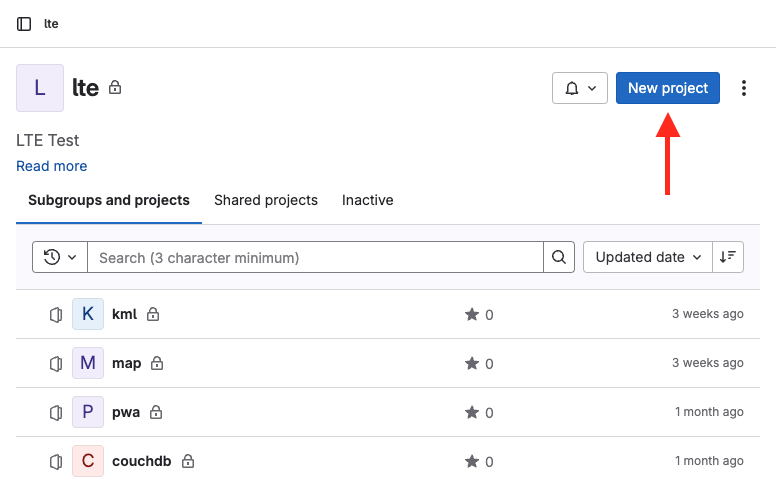
Atenção! O nome do repositório GIT deverá respeitar a sintaxe do nome de aplicações, ou seja, termo mínimo 3 caracteres e ser composto apenas por caracteres alfanuméricos minúsculos sem acentos e hífen.
Na próxima tela, você terá a escolha de criar um repositório em branco ou importar um repositório existente. Esta última opção pode ser utilizada quando se trata de uma aplicação que esteja sendo migrada e que já está sendo versionada pelo GIT (estando, p.e., no GitHub ou outra plataforma similar).
Atenção! A branch principal (trunk) do projeto deve obrigatoriamente se chamar
main. Se o repositório estiver utilizando outro nome (tal comomaster,developmentou qualquer variante) renomeie-a paramainantes de prosseguir.
Se estiver criando um repositório vazio para, posteriormente, por meio de um scaffold inicializar o código fonte em determinada linguagem e/ou arcabouço de desenvolvimento, recomenda-se criar um “blank project” e inicializá-lo com o README.
É necessário que o Embrapa I/O reconheça este repositório como uma aplicação para que esta seja criada também nas ferramentas satélites (Matomo, Sentry e SonarQube), provendo assim os identificadores necessários para configurar a integração do código-fonte com estas ferramentas. Assim, é necessário configurar manualmente os metadados da aplicação. Para isso, crie um diretório na raiz denominado .embrapa e, dentro dele, um arquivo settings.json com o seguinte conteúdo:
{
"boilerplate": "_",
"platform": "javascript",
"label": "",
"description": "",
"references": [],
"maintainers": [],
"variables": {
"default": [],
"alpha": [],
"beta": [],
"release": []
},
"orchestrators": [ "DockerCompose" ]
}
Depois será necessário rever este arquivo mas, para um primeiro momento, utilize este conteúdo acima alterando apenas o valor do atributo platform para a linguagem predominante na aplicação que será desenvolvida, dentre as seguintes opções: android, apple, dart, dotnet, electron, elixir, flutter, go, java, javascript, kotlin, native, node, php, python, react-native, ruby, rust, unity e unreal.
Atenção! Repare que o valor do atributo boilerplate é um underscore (carácter
_). Não altere este valor!
Uma vez que este arquivo de metadados tenha sido criado no repositório, este pode agora pode ser vinculado a uma aplicação homônima por meio da dashboard. Para isso, no card do projeto clique em “Nova App”, aceite os termos do disclaimer e, no passo seguinte, selecione no campo “Escolha um modelo (boilerplate)…” a opção “Repositório pré-existente”. Em seguida, insira o nome Unix do repositório no GitLab no campo indicado (deve ser exatamente o mesmo nome) e clique em “Criar App”.
Agora, será necessário codificar a nova aplicação ou adaptar o código-fonte existente realizando alguns procedimentos (mas não todos) que são tratados no artigo sobre desenvolvimento e disponibilização de boilerplates. Mais especificamente, será necessário:
- Aplicar as diretrizes de boas práticas para criação de aplicações;
- Integrar sua aplicação ao Sentry (error tracking), ao Matomo (analytics) e ao SonarQube;
- Criar os arquivos de environment variables;
- Conteinerizar sua aplicação;
- Implementar os serviços-padrões de test, backup, restore e sanitize; e
- Configurar adequadamente os metadados e os orquestradores.
Atenção! Repare que no último passo o arquivo
.embrapa/settings.jsonserá revisitado. Isto é necessário para complementá-lo com os valores padrão das variáveis de ambiente e a configuração de orquestradores, quando aplicável.
Pronto! Feito isso o Embrapa I/O irá criar, após algum tempo, a aplicação nas ferramentas satélites e expor no card as informações necessárias de configurações. Estando tudo certo será possível aplicar todos os pipelines e processos de DevOps, assim como em qualquer aplicação criada a partir de um boilerplate.