De forma geral, as aplicações da plataforma Embrapa I/O são forks de repositórios pré-existentes denominados boilerplates. Estes repositórios são aplicações funcionais, em determinada linguagem de programação ou framework, já estruturadas para funcionar corretamente nos pipelines e processos de DevOps da plataforma. A ideia é fomentar a padronização e o reuso de código-fonte. Neste tutorial veremos como configurar corretamente um novo boilerplate para distribuí-lo no catálogo da plataforma, de modo a possibilitar que outras equipes de desenvolvimento de ativos digitais possam fazer uso.
Para criar e disponibilizar seu boilerplate, você precisará seguir os seguintes passos:
- Crie uma “aplicação-base”;
- Integre ao Sentry (para error tracking);
- Integre ao Matomo (para analytics);
- Integre ao SonarQube (para code quality e secure analysis);
- Crie os arquivos de environment variables;
- Utilize as keywords de customização;
- Containerize seu boilerplate;
- Implemente os “serviços-padrões”: test, backup, restore e sanitize;
- Configure os metadados;
- Configure outros orquestradores;
- Documente e inclua a licença; e
- Distribua o boilerplate.
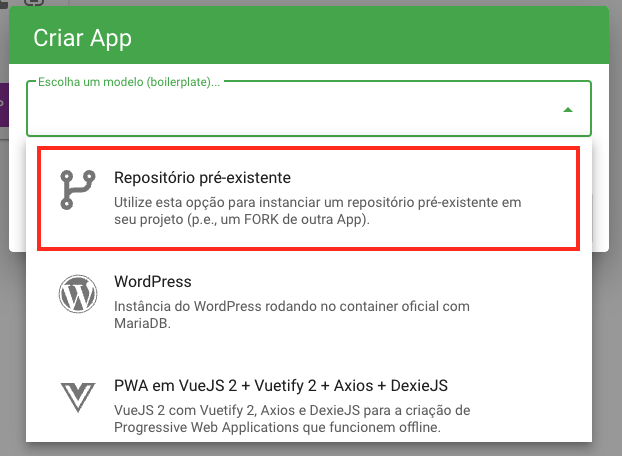
É possível criar um repositório de aplicação sem utilizar um boilerplate. Esta função é útil para instanciar na plataforma sistemas que antecedem o próprio Embrapa I/O. Entretanto, será necessário criar manualmente um repositório no GitLab e adaptar seu código fonte de forma que ele tenha toda a estrutura de pastas e arquivos requeridos para um boilerplate (ou seja, seguir os mesmos passos aqui descritos). Em seguida, no momento de criar a aplicação pela dashboard, selecione a opção de um “repositório pré-existente” (conforme a imagem abaixo).
1. Crie uma “aplicação-base”
O primeiro passo para iniciar a construção de seu boilerplate é criar uma aplicação funcional. Esta aplicação terá funcionalidades que são requisitos comuns de ativos digitais para a agricultura, de forma que o reúso deste código-base seja demandado. Por exemplo, poderíamos ter dois boilerplates de PWA utilizando os frameworks VueJS e Vuetify: um com sistema de login de usuários e outro sem. No catálogo de boilerplates o usuário poderia escolher qual utilizar tomando esta característica como base.
Atenção! O boilerplate deve ser uma aplicação com padrões rigorosos de qualidade de código, bem como utilizando as versões mais recentes, LTS, da linguagem e arcabouço de programação. Por exemplo, se estiver sendo criado em PHP, espera-se que esteja plenamente aderente aos PHP Standards Recommendations.
Assim, é fortemente recomendado que a criação de um boilerplate tenha como ponto de partida o Get Started do próprio arcabouço de programação. A imensa maioria dos frameworks modernos possuem ferramentas CLI do tipo standard tooling, que permitem a criação de estruturas padronizadas de projetos de software. Adicionalmente, priorize o uso de linguagens, arcabouços e pacotes que tenham licença open source permissivas, de forma a não “contaminar” o licenciamento da aplicação final. Por fim, tenha em mente que softwares são descontinuados. Portanto, para garantir uma vida longa e próspera ao seu boilerplate (e às aplicações derivadas dele), dê preferência a tecnologias consolidadas, com vastas comunidades e que tenham se provado no tempo. Tome como exemplos: Go Gin Gonic, Java Spring Boot, PHP Laravel, PHP Symfony, Python Django, ReactJS, React Native e VueJS/Vuetify.
Todos os boilerplates da plataforma ficam disponíveis publicamente no mesmo grupo de repositórios no GitLab. Você pode iniciar a criação de seu boilerplate em um repositório de aplicação dentro de um projeto seu na plataforma e, posteriormente, efetuar um fork para este grupo, ou solicitar a criação de um novo repositório dentro do grupo. Para todos os efeitos, a construção do boilerplate seguirá as diretrizes de uma aplicação convencional da plataforma, tal como o controle de issues e milestones.
Após criar a aplicação-base, você deverá customizá-la. Antes de começar a alterá-la, entretanto, verifique se existem ferramentas do tipo linter e formatter devidamente configuradas em sua IDE para a linguagem de programação que está utilizando. Falamos mais sobre isso na seção de boas práticas de desenvolvimento. É importante também configurar o EditorConfig. Como sugestão, crie um arquivo .editorconfig na raiz com o seguinte conteúdo:
[*]
charset = utf-8
end_of_line = lf
indent_size = 2
indent_style = space
insert_final_newline = true
trim_trailing_whitespace = true
[*.md]
trim_trailing_whitespace = false
Inicie a customização da aplicação-base incluindo aspectos que são comumente utilizados nos ativos digitais da Embrapa. Por exemplo, uma identidade visual aderente aos padrões estabelecidos pela área de comunicação, a logo da Empresa conforme o manual de uso, estrutura de menus, cabeçalho e rodapé, e telas que são normalmente padronizadas (p.e., a tela de “Sobre”). Adicionalmente, inclua funcionalidades mais complexas que caracterizem seu boilerplate, tal como requisitos não-funcionais (p.e., registro e login de usuários) ou mesmo funcionais (p.e., cadastro e gestão de fazendas). O domínio de negócio dos ativos digitais da plataforma Embrapa I/O é abrangente, porém bem definida: “o agronegócio”. Portanto, existem requisitos funcionais que serão de uso comum.
Caso esteja desenvolvendo o boilerplate para uma API Web, comprometa-se em torná-lo aderente ao AgroAPI, de forma que as aplicações criadas a partir dele possam compor o catálogo da Embrapa quando forem publicadas. Simuladores, algoritmos de aprendizado de máquina, visão computacional e artefatos de software especializados de forma geral, devem ser encapsulados em componentes específicos. Neste caso, recomenda-se que tenham seu próprio repositório de código e sejam integrados nas aplicações na forma de pacotes privados (gerenciados por dependency managers, tal como o composer, o npm, o gradle ou o maven). Assim, um boilerplate para uma aplicação TensorFlow.js, por exemplo, seria na verdade um pacote NPM. No capítulo sobre integração são detalhados outros formatos de aplicação, tal como remotes para compor micro-frontends.
2. Integre ao error tracking
Conforme já detalhado anteriormente, a plataforma Embrapa I/O é integrada à ferramenta Sentry, de error tracking. Assim, no momento em que um projeto ou uma aplicação é criada pela dashboard da plataforma, o autômato Genesis cria a entidade correlata na ferramenta Sentry e atribui a equipe. Pela dashboard será então possível à equipe de desenvolvimento do ativo obter o DSN de error tracking.
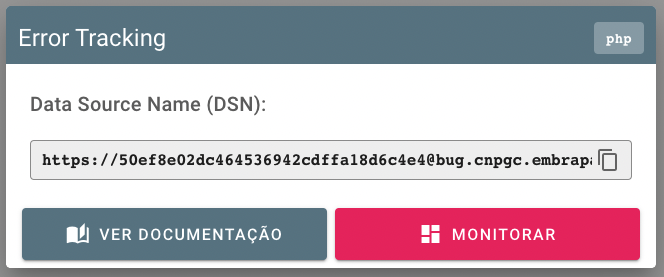
Para que funcione corretamente, será necessário preparar o boilerplate para o Sentry. Este possui SDKs específicos para diversas linguagens e arcabouços de programação. Por exemplo, para utilizar em um PWA em VueJS o seguinte trecho de código foi adicionado ao bootstrap da aplicação:
import * as Sentry from '@sentry/vue'
import { BrowserTracing } from '@sentry/tracing'
Sentry.init({
Vue,
dsn: process.env.VUE_APP_SENTRY_DSN,
release: process.env.VUE_APP_VERSION.split('-')[0],
environment: process.env.VUE_APP_STAGE,
integrations: [
new BrowserTracing({
routingInstrumentation: Sentry.vueRouterInstrumentation(router),
tracingOrigins: ['localhost', window.location.hostname, /^\//]
})
],
tracesSampleRate: 1.0
})
Dentre as variáveis de ambiente acima, o DSN, a versão da build (no atributo release) e o estágio (no atributo environment) são injetados em tempo de deploy pela plataforma. A keyword %GENESIS_PROJECT_UNIX% é alterada pelo autômato Genesis no momento do provisionamento da aplicação a partir do boilerplate.
3. Integre ao analytics
Similar ao error tracking e conforme também já detalhado anteriormente, a plataforma Embrapa I/O é integrada à ferramenta Matomo, utilizada para rastrear e analisar ações de usuários nas aplicações. Assim, no momento em que um projeto ou uma aplicação é criada pela dashboard da plataforma, o autômato Genesis cria a entidade correlata na ferramenta Matomo e atribui a equipe. Pela dashboard será então possível à equipe de desenvolvimento do ativo obter o identificador único de rastreamento (“Matomo Site ID”).

Para que funcione corretamente, será necessário preparar o boilerplate para o Matomo incluindo um código de rastreamento. Por exemplo, para utilizar em um PWA em VueJS o seguinte trecho de código foi adicionado ao router da aplicação (/src/router/index.js):
import VueMatomo from 'vue-matomo'
Vue.use(VueMatomo, {
host: 'https://hit.embrapa.io',
siteId: process.env.VUE_APP_MATOMO_ID,
router: router,
preInitActions: [
['setCustomDimension', 1, process.env.VUE_APP_STAGE],
['setCustomDimension', 2, process.env.VUE_APP_VERSION]
]
})
Dentre as variáveis de ambiente acima, o siteId, o estágio e a versão da build são injetados em tempo de deploy pela plataforma.
Caso esteja configurando o Matomo em um boilerplate para aplicações do tipo server-side, é possível passar o token_auth no código de rastreamento para gerar relatórios analíticos mais detalhados. O Embrapa I/O injeta a variável de ambiente MATOMO_TOKEN com a chave para a API. Esta chave tem permissão de escrita no site e, por conta disso, é um dado sensível para a segurança das aplicações. Assim, valor real do token_auth é injetado apenas nos serviços de deploy e restart das aplicações. Nos demais serviços (tal como de validate ou backup) o valor injetado na variável MATOMO_TOKEN é uma chave aleatória, sem real permissão de acesso à API do Matomo.
Atenção! Por questão de segurança, jamais utilize a variável
MATOMO_TOKENem aplicações de frontend ou exponha seu valor na interface do usuário!
Um exemplo de uso do token_auth do Matomo injetado pelo Embrapa I/O pode ser visto no código PHP abaixo:
require __DIR__ . '/vendor/autoload.php';
if (defined ('MATOMO_ID') && defined ('MATOMO_URL') && defined ('MATOMO_STAGE') && defined ('MATOMO_VERSION')) {
$matomo = new MatomoTracker((int) MATOMO_ID, MATOMO_URL);
if (defined ('MATOMO_TOKEN') && trim (MATOMO_TOKEN) != '') $matomo->setTokenAuth (MATOMO_TOKEN);
$matomo->setCustomDimension(1, MATOMO_STAGE);
$matomo->setCustomDimension(2, MATOMO_VERSION);
$matomo->doTrackPageView($pageTitle);
}
Neste código está sendo utilizado o pacote Matomo PHP Tracker, instalado via PHP Composer, que permite realizar requisições específicas à API de rastreamento do Matomo.
4. Integre à ferramenta de code quality e secure analysis
O SonarQube é uma popular ferramenta de análise estática usada no processo de revisão automática de código. Possui suporte a 29 linguagens de programação e capacidade de detectar bugs, código duplicado, cobertura de testes de software (como testes unitários), alta complexidade ciclomática, entre outros problemas no código-fonte.
A ferramenta está integrada à plataforma Embrapa I/O e pode, portanto, efetuar a análise do código-fonte de qualquer aplicação da plataforma (desde que a linguagem de programação seja suportada). Para permitir que esta análise seja realizada, é necessário inserir na raiz do boilerplate o arquivo .gitlab-ci.yml com o seguinte conteúdo:
image:
name: sonarsource/sonar-scanner-cli:11
entrypoint: [""]
variables:
SONAR_USER_HOME: "${CI_PROJECT_DIR}/.sonar"
GIT_DEPTH: "0"
stages:
- build-sonar
build-sonar:
stage: build-sonar
cache:
policy: pull-push
key: "sonar-cache-$CI_COMMIT_REF_SLUG"
paths:
- "${SONAR_USER_HOME}/cache"
- sonar-scanner/
script:
- >
sonar-scanner
-Dsonar.host.url="${SONAR_HOST_URL}"
-Dsonar.projectKey="${CI_PROJECT_NAMESPACE}_${CI_PROJECT_NAME}"
-Dsonar.qualitygate.wait=true
allow_failure: true
rules:
- if: $CI_PIPELINE_SOURCE == 'merge_request_event'
- if: $CI_COMMIT_BRANCH == 'main'
5. Crie os arquivos de environment variables
Na plataforma as aplicações são parametrizadas por meio de variáveis de ambiente, que são injetadas diretamente durante os processos automatizados (validate, deploy, backup, restart, etc). Os principais arquivos utilizados são:
.env.io: é injetado diretamente na chamada de linha de comando e, portanto, as variáveis neste arquivo terão precedência sobre todas as demais;.env.sh: substitui o arquivo acima quando são chamados serviços do tipo CLI (test,sanitize,backupourestore); e.env: é carregado pelo Docker Compose (veja abaixo) a partir da raiz da aplicação.
Estes arquivos, portanto, são gerados pela plataforma e não devem constar no boilerplate. Ao invés disso, devem estar listados no arquivo .gitignore de forma a não serem versionados pelo GIT. Assim, para disponibilização junto ao boilerplate, é recomendado criar os arquivos acima, porém com o sufixo .example (estes sim versionados pelo GIT). Desta forma, os desenvolvedores que utilizarem o boilerplate iniciarão a customização da aplicação copiando e renomeando estes arquivos para remover o sufixo.
As variáveis que compõem o arquivo .env.io.example são:
COMPOSE_PROJECT_NAME=%GENESIS_PROJECT_UNIX%_%GENESIS_APP_UNIX%
COMPOSE_PROFILES=development
IO_SERVER=localhost
IO_PROJECT=%GENESIS_PROJECT_UNIX%
IO_APP=%GENESIS_APP_UNIX%
IO_STAGE=development
IO_VERSION=%GENESIS_VERSION%
IO_DEPLOYER=first.surname@embrapa.br
SENTRY_DSN=GET_IN_DASHBOARD
MATOMO_ID=%GENESIS_MATOMO_ID%
MATOMO_TOKEN=
Acima as variáveis estão sendo setadas com valores propícios ao ambiente de desenvolvimento. Para distribuição do seu boilerplate, sugere-se utilizar algo semelhante. Repare na presença de keywords (entre os caracteres %), que serão explicadas em seguida. Ao copiar e renomear o arquivo (retirando o sufixo .example) o desenvolvedor da aplicação precisará ajustar estes valores, tal como inserir o DSN correto no Sentry.
As variáveis do arquivo .enc.cli.example serão idênticas às acima, com a exceção da variável COMPOSE_PROFILES, que deverá ser setada com o valor cli.
As variáveis do arquivo .env.example deverão ser as mesmas que são pré-carregadas para a configuração da build. Isto será explicado mais adiante, no passo de configuração dos metadados. A equipe de criação do boilerplate irá definir quais variáveis serão estas. Para fins de exemplificação, considere as seguintes variáveis do boilerplate do WordPress:
PORT=8081
DB_ROOT_PASSWD=secret
DB_PASSWD=secret
DATA_WP=%GENESIS_PROJECT_UNIX%_%GENESIS_APP_UNIX%_wp
BACKUP=%GENESIS_PROJECT_UNIX%_%GENESIS_APP_UNIX%_backup
WP_DEBUG=true
WP_ALLOW_MULTISITE=false
6. Utilize as keywords de customização
De forma a permitir ao autômato Genesis realizar a customização de alguns aspectos da aplicação, são disponibilizadas algumas palavras-chave de uso reservado (keywords) que são substituídas no momento do provisionamento a partir do boilerplate. São elas:
%GENESIS_PROJECT_UNIX%: Nome unix do projeto;%GENESIS_PROJECT_NAME%: Nome legível do projeto;%GENESIS_APP_UNIX%: Nome unix da aplicação;%GENESIS_ACTUAL_YEAR%: Ano atual, com 4 dígitos;%GENESIS_VERSION%: Um número de versão fictício, no padrão “0.YY.MM-dev.1”; e%GENESIS_MATOMO_ID%: Identificador único gerado e utilizado pelo Matomo.
Você pode optar por utilizar ou não estas keywords no seu boilerplate. O autômato irá substituí-las em todos os arquivos não-ocultos (com exceção dos arquivos .env.example, .env.io.example e .env.sh.example, onde também serão substituídas).
7. Containerize seu boilerplate
Normalmente, no próprio site da linguagem ou arcabouço de desenvolvimento utilizado há documentação sobre como conteinerizar o software desenvolvido utilizando o Docker. Veja como exemplo o tutorial “Dockerize Vue.js App” na documentação oficial do VueJS.
Algumas vezes, em ambiente de desenvolvimento, pode ser preferível não utilizar containers, porém para tornar a aplicação derivada do boilerplate apta ao deploy na plataforma, será necessário conteinerizar. Claro, isto não se aplica a aplicações que naturalmente não serão distribuídas na Web, tal como código nativo para Google Android (em Kotlin ou Java), código nativo para Apple iOS (em Swift ou Objective-C) ou artefatos de software especializados encapsulados em pacotes para gerenciadores de dependência, como citado anteriormente.
A plataforma Embrapa I/O é agnóstica quanto ao orquestrador de containers em nuvem, podendo trabalhar com diversas soluções. Mas padroniza o ambiente local de desenvolvimento com o uso de Docker Compose, sendo este também um dos drivers de orquestração em nuvem. Assim, para fins desta documentação, utilizaremos o Docker Compose para exemplificar o processo de conteinerização.
Conforme comentado previamente no capítulo de introdução, existem alguns serviços que precisam ser disponibilizados no stack de containers da aplicação: backup, restore, sanitize e test. Para entender melhor o papel de cada um, observe o arquivo docker-compose.yaml de um boilerplate para instanciar o WordPress:
services:
db:
image: mariadb:latest
restart: unless-stopped
volumes:
- data_db:/var/lib/mysql
networks:
- stack
environment:
MYSQL_ROOT_PASSWORD: ${DB_ROOT_PASSWD}
MYSQL_DATABASE: ${IO_PROJECT}_${IO_APP}
MYSQL_USER: wordpress
MYSQL_PASSWORD: ${DB_PASSWD}
healthcheck:
test: mysql ${IO_PROJECT}_${IO_APP} --user=wordpress --password='${DB_PASSWD}' --silent --execute "SELECT 1;"
interval: 20s
timeout: 10s
start_period: 20s
retries: 5
wordpress:
image: 127.0.0.1:5000/${IO_PROJECT}_${IO_APP}_${IO_STAGE}_wordpress
build: .
depends_on:
- db
volumes:
- data_wp:/var/www/html
networks:
- stack
ports:
- ${PORT}:80
restart: unless-stopped
environment:
WORDPRESS_DB_HOST: db
WORDPRESS_DB_USER: wordpress
WORDPRESS_DB_PASSWORD: ${DB_PASSWD}
WORDPRESS_DB_NAME: ${IO_PROJECT}_${IO_APP}
WORDPRESS_CONFIG_EXTRA: |
define('WP_DEBUG', ${WP_DEBUG});
define('WP_ALLOW_MULTISITE', ${WP_ALLOW_MULTISITE});
define('WP_SENTRY_PHP_DSN', '${SENTRY_DSN}');
define('WP_SENTRY_ERROR_TYPES', E_ALL & ~E_DEPRECATED & ~E_NOTICE & ~E_USER_DEPRECATED);
define('WP_SENTRY_VERSION', @array_shift(explode('-', '${IO_VERSION}')));
define('WP_SENTRY_ENV', '${IO_STAGE}' );
define('WP_MATOMO_URL', 'https://hit.embrapa.io');
define('WP_MATOMO_ID', ${MATOMO_ID});
define('WP_MATOMO_TOKEN', '${MATOMO_TOKEN}');
define('WP_MATOMO_STAGE', '${IO_STAGE}');
define('WP_MATOMO_VERSION', '${IO_VERSION}');
healthcheck:
test: curl --fail -s http://localhost:80/ || exit 1
interval: 20s
timeout: 10s
start_period: 30s
retries: 5
backup:
image: mariadb:latest
restart: "no"
environment:
MYSQL_ROOT_PASSWORD: ${DB_ROOT_PASSWD}
MYSQL_DATABASE: ${IO_PROJECT}_${IO_APP}
MYSQL_USER: wordpress
MYSQL_PASSWORD: ${DB_PASSWD}
depends_on:
- db
links:
- db
volumes:
- data_backup:/backup
- data_wp:/var/www/html
networks:
- stack
command: >
sh -c "set -ex &&
export BACKUP_DIR=${IO_PROJECT}_${IO_APP}_${IO_STAGE}_${IO_VERSION}_$$(date +'%Y-%m-%d_%H-%M-%S') &&
cd /backup && mkdir $$BACKUP_DIR &&
mysqldump --host db -uroot -p${DB_ROOT_PASSWD} ${IO_PROJECT}_${IO_APP} > $$BACKUP_DIR/db.sql &&
cp -R /var/www/html $$BACKUP_DIR/ &&
tar -czf $$BACKUP_DIR.tar.gz $$BACKUP_DIR &&
rm -rf /backup/$$BACKUP_DIR"
profiles:
- cli
restore:
image: mariadb:latest
restart: "no"
environment:
MYSQL_ROOT_PASSWORD: ${DB_ROOT_PASSWD}
MYSQL_DATABASE: ${IO_PROJECT}_${IO_APP}
MYSQL_USER: wordpress
MYSQL_PASSWORD: ${DB_PASSWD}
depends_on:
- db
links:
- db
volumes:
- data_backup:/backup
- data_wp:/var/www/html
networks:
- stack
command: >
sh -c "set -ex &&
export FILE_TO_RESTORE=${BACKUP_FILE_TO_RESTORE:-no_file_to_restore} &&
test -f /backup/$$FILE_TO_RESTORE &&
RESTORE_DIR=$$(mktemp) &&
tar -xf /backup/$$FILE_TO_RESTORE -C $$RESTORE_DIR --strip-components=1 &&
mysql --host db -uroot -p${DB_ROOT_PASSWD} ${IO_PROJECT}_${IO_APP} < $$RESTORE_DIR/db.sql &&
cp -Rf $$RESTORE_DIR/html/. /var/www/html &&
find /var/www/html -type d -exec chmod 755 {} \; &&
find /var/www/html -type f -exec chmod 644 {} \; &&
rm -rf $$RESTORE_DIR"
profiles:
- cli
sanitize:
image: mariadb:latest
restart: "no"
depends_on:
- db
links:
- db
networks:
- stack
command: >
sh -c "mysqlcheck --host db -uroot -p${DB_ROOT_PASSWD} -o --auto-repair --flush ${IO_PROJECT}_${IO_APP}"
profiles:
- cli
networks:
stack:
external: true
name: ${IO_PROJECT}_${IO_APP}_${IO_STAGE}
volumes:
data_wp:
name: ${DATA_WP}
external: true
data_db:
name: ${DATA_DB}
external: true
data_backup:
name: ${BACKUP}
external: true
Observe que as variáveis de ambiente utilizadas acima são as mesmas injetadas pelos arquivos .env e .env.io, nos exemplos discutidos anteriormente. Os serviços que serão chamados por linha de comando (test, sanitize, backup e restore) possuem o profile: [ 'cli' ], indicando que serão carregados apenas quando o arquivo .env.sh for utilizado (onde é passado, especificamente, COMPOSE_PROFILES=cli). Um exemplo de chamada destes serviços seria portanto:
env $(cat .env.sh) docker-compose run --rm --no-deps backup
Quando for realizado o deploy do stack de containers, todos os demais serviços “não-CLI” serão carregados. Mais especificamente, o autômato Deployer irá injetar as variáveis do arquivo .env.io alterando conforme o environment. Assim, caso se trate de uma build em estágio alpha o COMPOSE_PROFILES terá o valor alpha. Isto possibilita que o usuário carregue determinados serviços apenas em determinados ambientes. Por exemplo, pode ser interessante ao desenvolvedor carregar a ferramenta phpMyAdmin para auditar seu BD quando a aplicação estiver em estágio alpha ou beta, mas não (por questão de segurança) quando estiver em estágio release.
É fortemente recomendado que todos os serviços “não-CLI” tenham o atributo de healthcheck devidamente configurado. Este atributo permite que as aplicações sejam monitoradas, agregando informação à dashboard da plataforma. O atributo restart destes serviços deve estar setado para unless-stopped, de forma a garantir maior resiliência da aplicação.
É muito importante que os volumes e a network sejam configurados corretamente. Para uso com os drivers do Docker Compose ou Docker Swarm, o autômato Deployer da plataforma executa uma série de validações. Dentre elas, somente são aceitos volumes e networks configurados com o atributo external igual à true. Assim, para instanciar a aplicação em ambiente de desenvolvimento, os desenvolvedores precisarão fazer algo do tipo:
docker network create agroproj_agroapp_development
docker volume create agroproj_agroapp_db
docker volume create --driver local --opt type=none --opt device=$(pwd)/data/wp --opt o=bind agroproj_agroapp_wp
docker volume create --driver local --opt type=none --opt device=$(pwd)/data/backup --opt o=bind agroproj_agroapp_backup
Em ambientes de deploy (alpha, beta e release) o volume será criado automaticamente utilizando o driver de storer configurado no cluster. Por exemplo, para um cluster com orquestrador Docker Compose utilizando como storer o NFSv4, teríamos algo do tipo:
docker volume create --driver local --opt type=nfs --opt o=addr=storage.sede.embrapa.br,rw --opt device=:/mnt/nfs/cluster.sede.embrapa.br/agroproj_agroapp_alpha_wp agroproj_agroapp_alpha_wp
Por segurança, todos os volumes e a network alocados no stack de containers são checados antes do deploy. Assim, não é possível uma aplicação referenciar e acessar o volume e/ou network de outra aplicação. Uma vez que os volumes e a network estejam criados, o desenvolvedor da aplicação poderá instanciá-la com o seguinte comando:
env $(cat .env.io) docker-compose up --force-recreate --build --remove-orphans -d --wait
Em ambientes de deploy que utilizem o driver do Docker Compose o comando será semelhante, porém existem algumas garantias para assegurar que não sejam, por exemplo, chamados serviços do tipo CLI.
Adicionalmente, repare no exemplo acima o serviço wordpress. Este serviço é buildado em tempo de deploy, ou seja, existe um arquivo Dockerfile para possibilitar sua build. Entretanto foi configurada uma imagem com o valor 127.0.0.1:5000/${IO_PROJECT}_${IO_APP}_${IO_STAGE}_wordpress. Este recurso é utilizado para possibilitar o deploy em outros orquestradores, tal como o Docker Swarm. Neste caso, além de realizar a build, o Docker Compose irá registrar a imagem gerada no servidor de registro local do cluster, possibilitando o deploy no swarm na sequência.
8. Implemente os “serviços-padrões”
Conforme já comentado, existem alguns serviços do tipo CLI que são requeridos pela plataforma em todas as aplicações instanciadas. Assim, os boilerplates devem prover uma versão inicial destes serviços no stack de containers, que poderá ser aprimorada pelo desenvolvedor da aplicação posteriormente. Detalharemos mais cada um deles a seguir.
Um ponto que deve-se ter em mente é que nem sempre fará sentido a aplicação possuir alguns destes serviços. Por exemplo, uma aplicação do tipo PWA é executada inteiramente do lado do cliente, não tendo qualquer persistência de dados (ou estado) na nuvem. Assim, não faz sentido disponibilizar serviços de backup e restore. Nestes casos, visando não gerar problemas com a automação interna e externa à plataforma, recomenda-se o uso da imagem tianon/true nestes serviços, tal como segue:
backup:
image: tianon/true
restart: "no"
profiles:
- cli
restore:
image: tianon/true
restart: "no"
profiles:
- cli
a) test
Este serviço executa entre os processos de build e deploy do autômato de Deployer, aplicando os testes unitários (previamente implementados) na aplicação. Assim, antes de preparar o serviço, é necessário integrar uma biblioteca ou pacote para testes unitários e estabelecer um conjunto mínimo de testes que fará parte do boilerplate e poderá, mais tarde, ser aprimorado pelo desenvolvedor da aplicação.
Atenção! Na versão de PoC da plataforma este serviço ainda não está sendo utilizado.
b) backup
A plataforma Embrapa I/O fornece, por meio da dashboard, uma funcionalidade para geração de backups por demanda para os mantenedores dos projetos de ativos digitais. Para que funcione corretamente, é necessário que exista o serviço backup na stack de containers da aplicação. Além disso, deve-se configurar um volume utilizando a palavra reservada backup. Veremos a seguir como deixar pré-estabelecido no boilerplate este volume.
De forma geral, o serviço deverá gerar os dumps de todos os BDs, copiar os arquivos de upload e tudo mais que for necessário para possibilitar a restauração do estado atual da aplicação, compactar em um arquivo no formato %GENESIS_PROJECT_UNIX%_%GENESIS_APP_UNIX%_${STAGE}_${VERSION}_$$(date +'%Y-%m-%d_%H-%M-%S').tar.gz e salvar no volume backup.
Na seção anterior é possível observar este e os demais serviços CLI devidamente configurados no docker-compose.yaml para um boilerplate do WordPress. Repare que naquele exemplo é realizado o dump do MariaDB e é copiada integralmente a pasta /var/www/html, com todos os arquivos do WordPress. Quando da execução do processo de backup, o arquivo .tar.gz resultante é copiado para o volume backup que é então montado pelo autômato Doctor, que atribui uma URL (protegida por login e senha de acesso) e informa os mantenedores do projeto via e-mail.
Repare que este serviço é essencial para manter a autonomia dos mantenedores dos projetos de ativos digitais, reforçando as diretrizes de DevOps adotadas pela plataforma Embrapa I/O.
c) restore
O serviço de restore objetiva, principalmente, auxiliar os mantenedores do projeto tornando rápida e fácil a recuperação do backup da aplicação. Mais especificamente, este serviço irá receber um arquivo do tipo .tar.gz por meio da variável de ambiente BACKUP_FILE_TO_RESTORE, passada por linha de comando, descompactar e restaurar todos os dados nos containers que formam a aplicação:
env $(cat .env.sh) BACKUP_FILE_TO_RESTORE=agroproj_agroapp_alpha_1.22.7-alpha.34_2022-06-23_09-30-04.tar.gz docker-compose run --rm --no-deps restore
d) sanitize
A plataforma Embrapa I/O implementa um processo de higienização/otimização das aplicações. Este processo pode ser relevante para aplicações que tenham tarefas de garbage collection, análise/reparação/otimização de esquemas em seus BDs, limpeza de cache, etc. Nada impede, obviamente, a equipe de desenvolvimento da aplicação desenvolver seus próprios schedular jobs para executar as mesmas tarefas na forma de containers no stack da aplicação. Entretanto, este serviço visa simplificar este trabalho.
No docker-compose.yaml do exemplo da seção anterior é utilizada a ferramenta de linha de comando mysqlcheck para efetuar a manutenção das tabelas do banco de dados MariaDB utilizado no WordPress. Outras ferramentas e comandos similares que podem ser utilizadas neste serviço são o vacuum do PostgreSQL, o shrink do SQL Server, o compact do MongoDB, etc.
9. Configure os metadados
Todo boilerplate e, consequentemente, toda aplicação na plataforma Embrapa I/O possui um diretório na raiz denominado .embrapa. Neste diretório ficam armazenados todos os metadados necessários à parametrização dos processos de DevOps da plataforma. Assim, com exceção do orquestrador Docker Compose, cujo arquivo de configuração fica na raiz da aplicação pois também é utilizado em ambiente de desenvolvimento, as configurações que parametrizam as ferramentas de orquestração de containers (Docker Swarm, Kubernetes, LXC, etc) e PaaS (RedHat OpenShift, AWS, Microsoft Azure, Google Cloud, Heroku, etc) devem estar, sempre que possível, neste diretório.
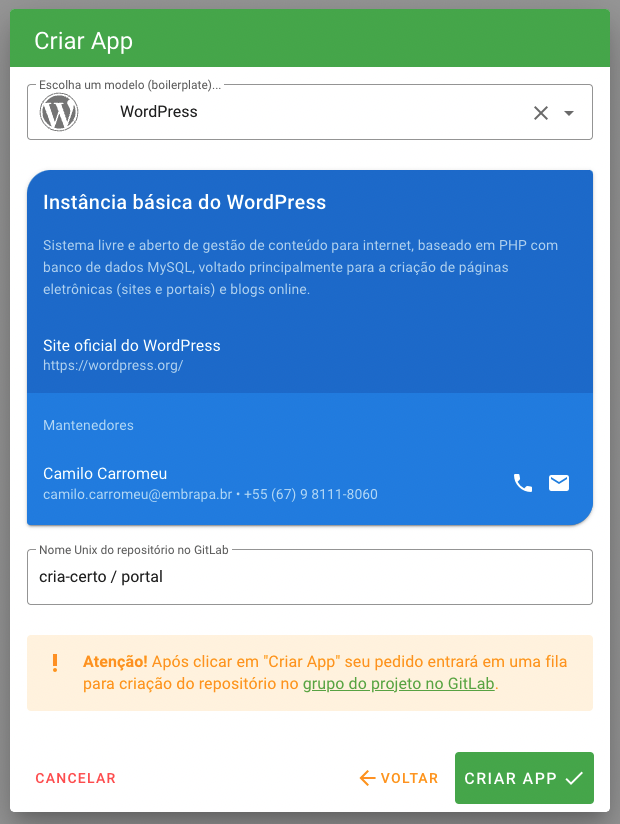
Além disso, neste diretório fica o arquivo settings.json, que possui informações necessárias utilizadas pelos diversos componentes do Embrapa I/O. Para cada boilerplate criado, será necessário configurar corretamente este arquivo. Vamos tomar como exemplo o boilerplate para WordPress:
{
"boilerplate": "wordpress",
"platform": "php",
"label": "Instância básica do WordPress",
"description": "Sistema livre e aberto de gestão de conteúdo para internet, baseado em PHP com banco de dados MySQL, voltado principalmente para a criação de páginas eletrônicas (sites e portais) e blogs online.",
"references": [
{ "label": "Site oficial do WordPress", "url": "https://wordpress.org/"}
],
"maintainers": [
{ "name": "Camilo Carromeu", "email": "camilo.carromeu@embrapa.br", "phone": "+55 (67) 9 8111-8060" }
],
"variables": {
"default": [
{ "name": "PORT", "type": "PORT" },
{ "name": "DB_ROOT_PASSWD", "type": "PASSWORD" },
{ "name": "DB_PASSWD", "type": "PASSWORD" },
{ "name": "DATA_WP", "value": "wp", "type": "VOLUME" },
{ "name": "BACKUP", "value": "backup", "type": "VOLUME" },
{ "name": "WP_DEBUG", "value": "true", "type": "TEXT" },
{ "name": "WP_ALLOW_MULTISITE", "value": "false", "type": "TEXT" }
],
"alpha": [],
"beta": [],
"release": [
{ "name": "WP_DEBUG", "value": "false", "type": "TEXT" }
]
},
"orchestrators": [ "DockerCompose", "DockerSwarm" ]
}
O atributo boilerplate deve conter o nome único do boilerplate em toda a plataforma e deve seguir o padrão unix de nomes de entidades (/^[a-z0-9-]{3,}$/).
Atenção! Caso esteja apenas adequando uma aplicação legada para ficar aderente à plataforma, insira o valor “_” (underscore) no atributo
boilerplate.
O atributo platform corresponde ao SDK do Sentry que deverá ser utilizado neste boilerplate. As keywords para as plataformas aceitas pelo Sentry são: android, apple, dart, dotnet, electron, elixir, flutter, go, java, javascript, kotlin, native, node, php, python, react-native, ruby, rust, unity e unreal. Defina corretamente a palavra-chave no atributo para assegurar a melhor experiência dos desenvolvedores no monitoramento de erros da aplicação.
Os atributos label, description, references e maintainers (auto-explicativos) e são renderizados pela dashboard da plataforma no momento da escolha do boilerplate na criação de aplicações.
No atributo variables são inseridas as environment variables que parametrizam a aplicação, ou seja, as mesmas contidas no arquivo .env. A plataforma Embrapa I/O carrega estas variáveis, com seus respectivos valores padrão, no momento da configuração da build. Serão carregadas primeiro as variáveis do atributo default e, em seguida, sobrescrevendo estas, as variáveis dos atributos homônimos ao estágio da build que está sendo configurada (alpha, beta ou release). No exemplo acima, está sendo habilitado por padrão o debug (variável WP_DEBUG) para as builds em estágio de testes internos (alpha) e externos (beta), e desabilitado para as builds em produção (release).
Outro exemplo de uso é para setar o environment interno aos arcabouços de programação. Por exemplo, uma aplicação ASP.NET aceita os seguintes valores para a variável ASPNETCORE_ENVIRONMENT: Development, Staging, Staging_2 e Production (conforme a documentação). Assim, poderia ser configurado no arquivo .env.example do boilerplate a variável ASPNETCORE_ENVIRONMENT=Development, de forma que os desenvolvedores, ao renomearem o arquivo para iniciar a customização da aplicação, já usariam o valor correto para o environment de desenvolvimento. Nas configurações de metadados do boilerplate no arquivo settings.json, esta variável poderia ser setada no subgrupo alpha como Staging, em beta como Staging_2 e em release como Production. A mesma estratégia pode pode ser utilizada para a variável NODE_ENV, comumente utilizada em projetos em JavaScript, e demais correlatas em outras linguagens e arcabouços de programação.
Atenção! Durante a configuração da build os valores padrão para as variáveis definidos aqui, bem como aqueles gerados randomicamente, poderão ser alterados pelo usuário.
As variáveis definidas podem ser de cinco tipos:
- TEXT: Uma sequência de caracteres livre, porém sem espaços (
/^[^\s]*$/). Caso não seja passado um valor padrão (atributovalue), será deixado em branco. - PASSWORD: Utilizado para armazenar senhas. Uma sequência de caracteres livre, porém sem espaços (
/^[^\s]*$/). Caso não seja passado um valor padrão (atributovalue), será atribuída uma string randômica (/^[a-zA-Z0-9]{16}$/). - SECRET: Utilizado para armazenar chaves privadas. Uma sequência de caracteres livre, porém sem espaços (
/^[^\s]*$/). Caso não seja passado um valor padrão (atributovalue), será atribuída uma string randômica (/^[a-zA-Z0-9]{256}$/). - PORT: Utilizado para armazenar as portas expostas publicamente da aplicação. O valor desta variável será setado na configuração da build considerando as portas vagas do cluster escolhido para deploy.
- VOLUME: Utilizado para referenciar os volumes da aplicação. Os valores inseridos aqui serão utilizados na configuração da build, no passo de definição de volumes, para preencher automaticamente a lista dos volumes da aplicação.
- EMPTY: Força o uso de uma string vazia como valor da variável. Útil para desabilitar variáveis em determinados ambientes de deploy.
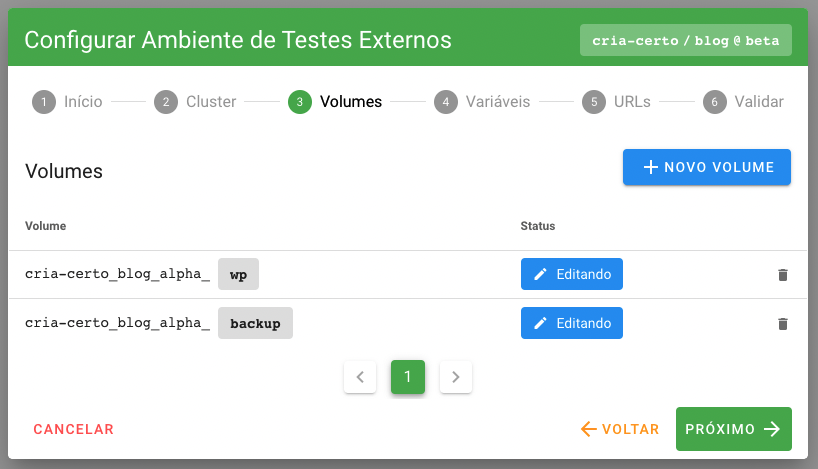
Repare que no “3º Passo - Volumes”, mostrado na imagem acima, a listagem de volumes foi pré-carregada de acordo com a variáveis deste tipo declaradas nos metadados do boilerplate utilizado na aplicação. Da mesma forma, todas as variáveis serão pre-carregadas no “4º Passo - Variáveis” com os valores definidos no settings.json ou gerados automaticamente. Na imagem abaixo é mostrado um exemplo da lista de variáveis pré-carregada (desconsidere as variáveis do tipo SERVER, que são aquelas presentes no arquivo .env.io e injetadas em tempo de deploy).
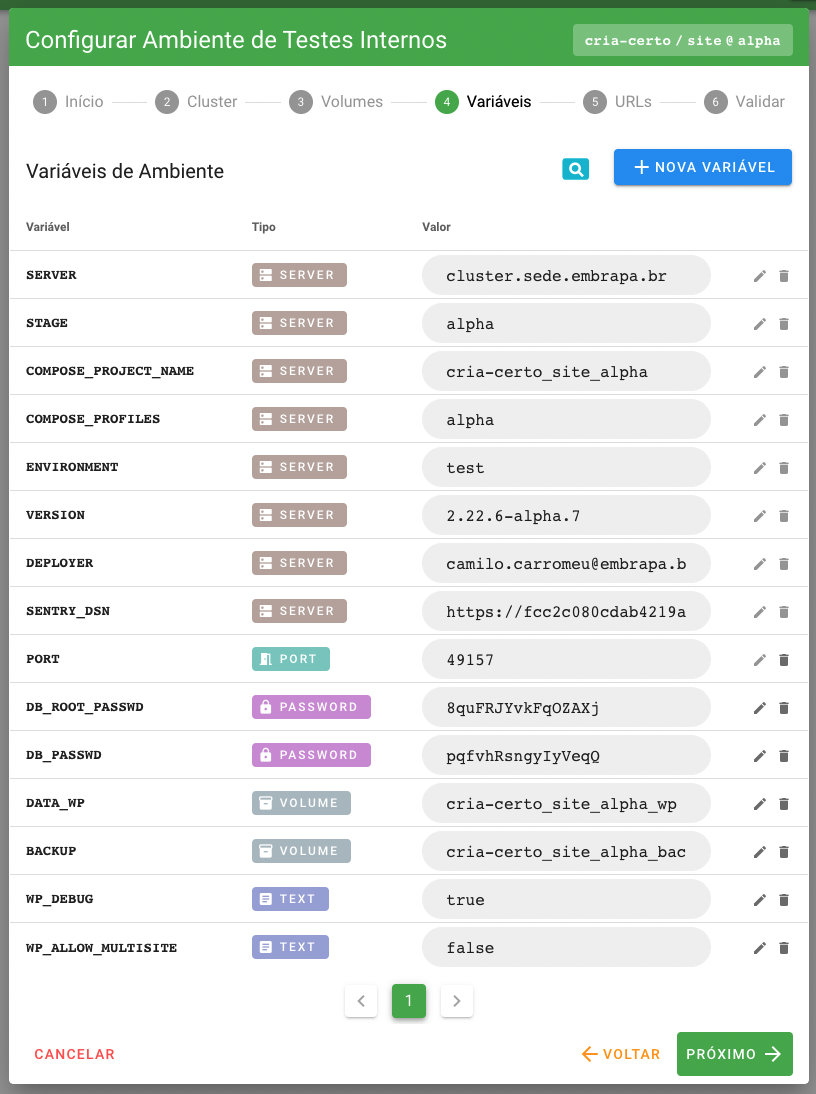
Por fim, o atributo orchestrators lista os orquestradores para os quais o boilerplate está homologado. Cada orquestrador irá exigir parâmetros específicos para permitir o deploy das aplicações. Por exemplo, para que o boilerplate esteja aderente ao Kubernetes, espera-se que exista um diretório “.embrapa/k8s” contendo os arquivos de configuração necessários. A equipe mantenedora do boilerplate deve, na medida do possível, configurá-lo e homologá-lo na maior quantidade possível de orquestradores aceitos pela plataforma Embrapa I/O.
10. Configure outros orquestradores
Conforme é detalhado no capítulo sobre a configuração de clusters, o Embrapa I/O trabalha, por padrão, com o orquestrador Docker Compose no ambiente de desenvolvimento, mas outros orquestradores podem ser utilizados nos ambientes remotos de deploy. Estas configurações de deployment para cada driver de orquestração deverão estar disponibilizadas no diretório de metadados .embrapa.
a) Docker Swarm
As configurações para deploy da aplicação em clusters com Docker Swarm deverão ser disponibilizadas na pasta .embrapa/swarm. Um arquivo principal de deploy, denominado deployment.yaml deverá estar na raiz desta pasta. Este arquivo deverá ser uma cópia dos docker-compose.yaml no diretório raiz da aplicação, porém somente com os serviços do profile de deploy.
Todos os serviços deverão ter uma imagem vinculada. Esta imagem deverá ser exatamente a mesma na declaração do serviço nos arquivos docker-compose.yaml e .embrapa/swarm/deployment.yaml. Em serviços que são ‘buildados’ em tempo de deploy, as imagens geradas deverão ser registradas no servidor local do Docker Registry. Por exemplo, considere o arquivo docker-compose.yaml mostrado no passo de conteinerização do boilerplate. Os arquivo deployment.yaml correlato seria:
services:
db:
image: mariadb:latest
environment:
MYSQL_ROOT_PASSWORD: ${DB_ROOT_PASSWD}
MYSQL_DATABASE: ${IO_PROJECT}_${IO_APP}
MYSQL_USER: wordpress
MYSQL_PASSWORD: ${DB_PASSWD}
volumes:
- data_db:/var/lib/mysql
networks:
- stack
healthcheck:
test: mysql ${IO_PROJECT}_${IO_APP} --user=wordpress --password='${DB_PASSWD}' --silent --execute "SELECT 1;"
interval: 1m30s
timeout: 10s
start_period: 30s
retries: 4
deploy:
restart_policy:
condition: on-failure
wordpress:
image: 127.0.0.1:5000/${IO_PROJECT}_${IO_APP}_${IO_STAGE}_wordpress
depends_on:
- db
volumes:
- data_wp:/var/www/html
ports:
- ${PORT}:80
networks:
- stack
environment:
WORDPRESS_DB_HOST: db
WORDPRESS_DB_USER: wordpress
WORDPRESS_DB_PASSWORD: ${DB_PASSWD}
WORDPRESS_DB_NAME: ${IO_PROJECT}_${IO_APP}
WORDPRESS_CONFIG_EXTRA: |
define('WP_DEBUG', ${WP_DEBUG});
define('WP_ALLOW_MULTISITE', ${WP_ALLOW_MULTISITE});
define('WP_SENTRY_PHP_DSN', '${SENTRY_DSN}');
define('WP_SENTRY_ERROR_TYPES', E_ALL & ~E_DEPRECATED & ~E_NOTICE & ~E_USER_DEPRECATED);
define('WP_SENTRY_VERSION', @array_shift(explode('-', '${IO_VERSION}')));
define('WP_SENTRY_ENV', '${IO_STAGE}' );
define('WP_MATOMO_URL', 'https://hit.embrapa.io');
define('WP_MATOMO_ID', ${MATOMO_ID});
define('WP_MATOMO_TOKEN', '${MATOMO_TOKEN}');
define('WP_MATOMO_STAGE', '${IO_STAGE}');
define('WP_MATOMO_VERSION', '${IO_VERSION}');
healthcheck:
test: curl --fail -s http://localhost:80/ || exit 1
interval: 1m30s
timeout: 10s
start_period: 30s
retries: 4
deploy:
restart_policy:
condition: on-failure
networks:
stack:
external: true
name: ${IO_PROJECT}_${IO_APP}_${IO_STAGE}
volumes:
data_wp:
name: ${DATA_WP}
external: true
data_backup:
name: ${BACKUP}
external: true
data_db:
name: ${DATA_DB}
external: true
No serviço wordpress é declarada a imagem 127.0.0.1:5000/${IO_PROJECT}_${IO_APP}_${IO_STAGE}_wordpress. Assim, o docker-compose.yaml será utilizado para realizar o build da aplicação e registrar as imagens que serão depois utilizadas no swarm.
O atributo deploy no arquivo deployment.yaml é específico do Docker Swarm. A plataforma Embrapa I/O restringe o que pode ser configurado neste atributo. Neste momento, é necessário que o valor de restart-policy seja condition: on-failure. O mode, caso seja setado, deve ter o valor global (mas é recomendado não configurá-lo). Os atributos resources e replicas não devem existir.
Os serviços do tipo CLI (backup, restore, sanitize e test), por sua vez, deverão estar separados em arquivos YAML próprios na pasta .embrapa/swarm/cli. Por exemplo, para um arquivo backup.yaml nesta pasta, teríamos:
services:
backup:
image: mariadb:latest
volumes:
- data_backup:/backup
- data_wp:/var/www/html
command: >
sh -c "set -ex &&
export BACKUP_DIR=${IO_PROJECT}_${IO_APP}_${IO_STAGE}_${IO_VERSION}_$$(date +'%Y-%m-%d_%H-%M-%S') &&
cd /backup && ls -l && mkdir $$BACKUP_DIR &&
mysqldump --host db -uroot -p${DB_ROOT_PASSWD} ${IO_PROJECT}_${IO_APP} > $$BACKUP_DIR/db.sql &&
cp -R /var/www/html $$BACKUP_DIR/ &&
tar -czf $$BACKUP_DIR.tar.gz $$BACKUP_DIR &&
ls -la /var/www/html &&
rm -rf /backup/$$BACKUP_DIR"
networks:
- stack
deploy:
restart_policy:
condition: none
networks:
stack:
external: true
name: ${IO_PROJECT}_${IO_APP}_${IO_STAGE}
volumes:
data_wp:
name: ${DATA_WP}
external: true
data_backup:
name: ${BACKUP}
external: true
Ao contrário do deployment.yaml, na declaração dos serviços CLI o atributo restart_policy deve ter condition: none, uma vez que estes são one-shot containers.
11. Documente e inclua a licença
É extremamente importante que, na raiz do repositório do boilerplate, tenha os arquivos README.md e LICENSE. O README.md conterá a documentação do boilerplate voltada para os usuários desenvolvedores. Ou seja, os usuários que irão derivar seu código-fonte para criar as aplicações finais. Existem modelos e templates de uso livre que podem auxiliar nesta documentação. Neste arquivo estarão presentes informações sobre o boilerplate, tal como:
- prints das telas, caso ele possua uma UI;
- as funcionalidades pré-implementadas, que são normalmente requisitos não-funcionais para as aplicações derivadas;
- as tecnologias utilizadas, tal como a linguagem de programação (e sua versão), frameworks, bibliotecas, pacotes, etc;
- uma seção de Getting Started, onde são listados os pré-requisitos e como realizar a instalação;
- exemplos de uso do boilerplate e de customizações possíveis;
- um roadmap com a lista do que já está implementado e de um eventual backlog;
- o passo-a-passo de como os usuários podem participar da equipe de mantenedores do boilerplate;
- informações de contato dos membros mantenedores; e
- uma seção de referências para documentação externa dos principais componentes e material de apoio.
Já no arquivo LICENSE estará presente a licença de uso e derivação do boilerplate em si. É fundamental que esta licença seja de código-aberto e extremamente permissiva, de forma a não “contaminar” a aplicação derivada. Por exemplo, é indesejável o uso de uma licença do tipo GNU GPL v3, uma vez que ela obriga todo código-fonte derivado a ter a mesma licença do original (e, desta forma, ser também open source). Como muitas aplicações aspiram a produtos com apelo mercadológico, o uso do boilerplate seria impossibilitado. Falamos mais sobre este assunto no capítulo de licenciamento.
Assim, como sugestão, recomendamos fortemente o uso da licensa MIT em todo boilerplate desenvolvido.
12. Distribua o boilerplate
Para distribuir o boilerplate para uso pela comunidade de desenvolvedores, será necessário disponibilizá-lo no grupo de repositórios /io/boilerplate do GitLab da plataforma, onde estará visível publicamente para todos os usuários.
Atenção! Após efetuar o fork da aplicação, criando o boilerplate, é necessário alterar a visibilidade no boilerplate para ‘Public’ (Settings » General » Visibility, project features, permissions » Project visibility).
Além disso, ele deverá constar e estar ativo no catálogo de boilerplates. Para ser inserido na listagem, os mantenedores precisarão passar para a equipe de suporte do Embrapa I/O o nome unix do boilerplate, um nome legível (rótulo), uma breve descrição (de uma linha) e um ícone que melhor represente as tecnologias utilizadas. Atualmente, os ícones permitidos são:
fa-android
fa-angular
fa-apple
fa-code-branch
fa-golang
fa-java
fa-js
fa-microsoft
fa-node-js
fa-php
fa-puzzle-piece
fa-python
fa-react
fa-vuejs
fa-wordpress
Parabéns! 🥳 Tendo seguido estes passos você disponibilizou um novo boilerplate que poderá ser utilizado pela comunidade Embrapa I/O no desenvolvimento de ativos digitais para a agropecuária.
Obrigado pela sua contribuição! 🤗