Conforme detalhado anteriormente, a plataforma Embrapa I/O adota uma metodologia de desenvolvimento baseada na entrega de melhorias contínuas e graduais. Desta forma, uma vez que o processo de codificação das aplicações se inicie, já é possível configurar os ambientes de estágio para entrega da aplicação para testadores internos (alpha testers), testadores externos (beta testers) e para os usuários finais em produção (release users).
Quando uma aplicação é disponibilizada em um determinado ambiente de estágio, denominamos esta combinação como uma build da aplicação. Seu nome será dado pela junção do nome unix do projeto (namespace), o nome unix da aplicação e o estágio (alpha, beta ou release):
project / app @ stage
Falamos mais sobre os estágios de maturidade e a definição de build no capítulo de introdução.
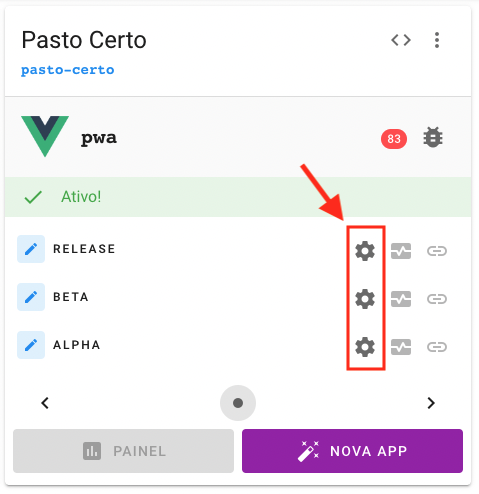
Uma vez que a aplicação tenha sido criada, já será possível configurar as builds para cada estágio. Para isso, será necessário a um mantenedor do projeto informar, por meio de um wizard, dados essenciais para o deploy da build. Inicialmente, o usuário precisará clicar no ícone em forma de “engrenagem” ao lado do estágio (alpha, beta ou release) que deseja configurar para gerar a build.
Passo 1: Disclaimer
O wizard de configuração da build tem 6 (seis) passos nos quais o usuário deverá preencher informações requeridas. O primeiro é o disclaimer, o qual o mantenedor do projeto deverá estar ciente.
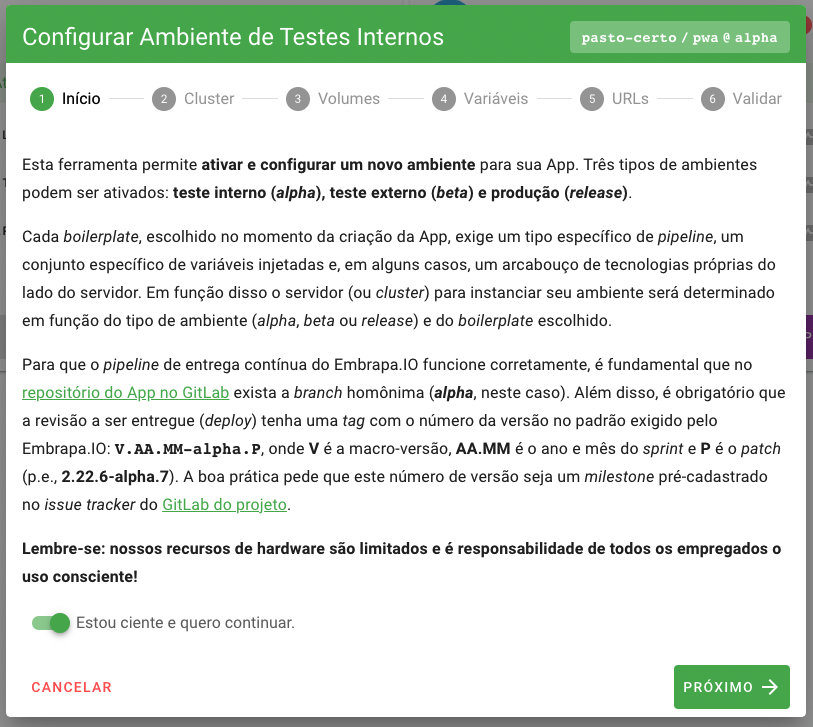
Repare que no canto superior direito do dialog do wizard é indicado o nome da build que está sendo configurada.
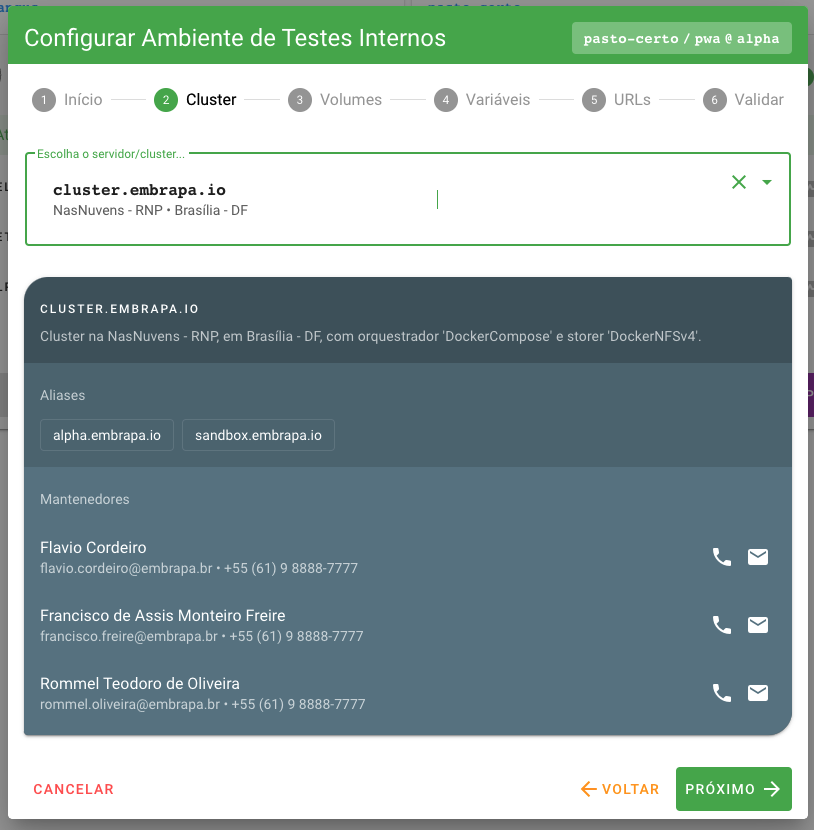
Passo 2: Cluster
No segundo passo o usuário deverá informa o cluster onde será realizado o deploy desta build da aplicação.
Atenção! Uma vez que tenha sido realizado o deploy no cluster escolhido, ele não poderá mais ser alterado.
Os clusters de deploy de builds podem estar em qualquer local (em Unidades da Embrapa, instituições e empresas parceiras ou serviços de cloud terceirizados) e podem utilizar diversas tecnologias de orquestração de containers homologadas para a plataforma. Falamos mais sobre clusters no capítulo de introdução e no tutorial sobre como configurar e disponibilizar um cluster.
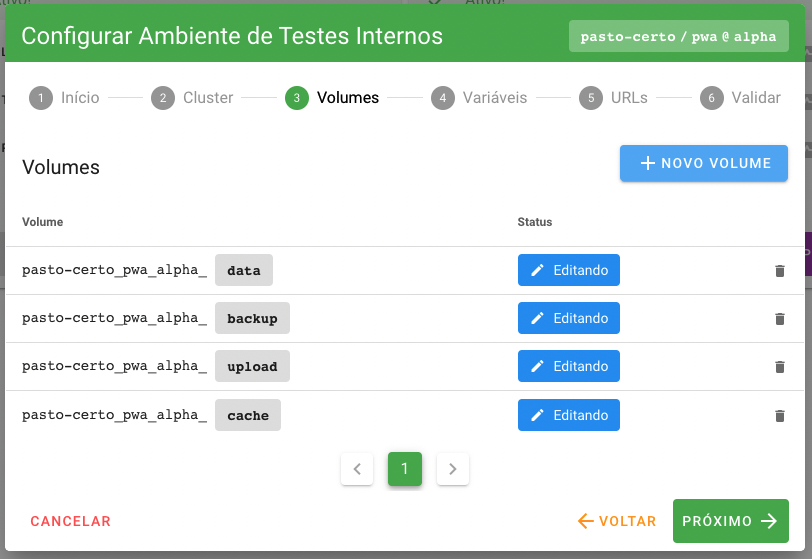
Passo 3: Volumes
Um volume é uma área de armazenamento independente utilizada pelas aplicações para persistir dados criados em tempo de execução. Um exemplo comum são arquivos de upload enviados para uma aplicação web. Nos clusters estas áreas serão criadas em servidores do tipo storage, específicos para armazenar grandes quantidades de dados.
Ao acessar pela primeira vez este passo na configuração da build, a plataforma carrega volumes que foram pré-configurados no boilerplate utilizado para instanciar a aplicação. A equipe mantenedora do boilerplate é responsável por “propor” uma configuração inicial que garanta a conteinerização da aplicação derivada. Neste passo, o usuário mantenedor do projeto pode alterar esta proposta inicial apagando volumes que não queira utilizar e criando outros. É necessário, no entanto, se atentar ao volume denominado backup, pois este é um volume coringa utilizado no processo de backup de builds.
Passo 4: Environment Variables
Neste passo o usuário irá configurar as variáveis de ambiente da build. Da mesma forma que ocorre em volumes, aqui serão pré-carregadas “variáveis iniciais”, proposta pela equipe mantenedora do boilerplate. O usuário poderá então remover, alterar e criar novas variáveis.
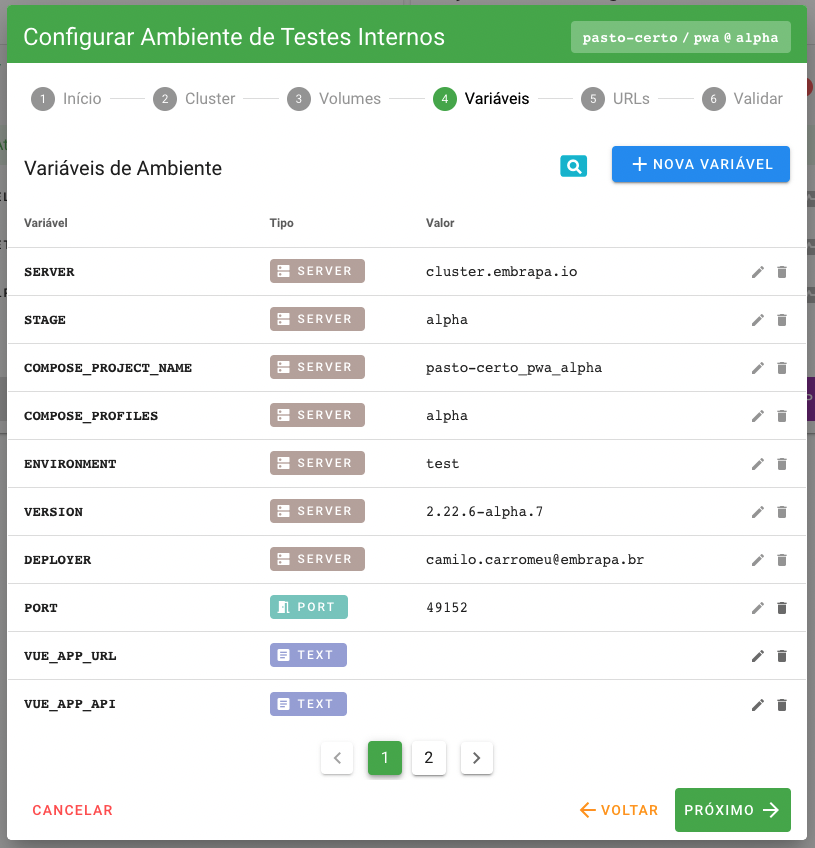
As variáveis de ambiente podem ser de 6 (seis) tipos:
- SERVER: São variáveis injetadas pelo autômato de deploy e não podem ser alteradas. Contém informações relevantes que podem ser utilizadas pela build em tempo de execução, tal como o estágio, o número da versão e o usuário que executou o deploy.
- TEXT: São variáveis de texto livre (plain text), cujo o conteúdo pode ser inserido pelo usuário. Não são aceitos, no entanto, nenhum tipo de caracter de espaço (o próprio espaço, tabulação, quebra de linha, etc).
- SECRET: São utilizadas para o registro de private keys, necessárias para sistemas de autenticação. Na configuração inicial da build a plataforma gera uma sequência randômica alfanumérica de 256 caracteres, mas o usuário pode alterar este valor.
- PASSWORD: Utilizadas para armazenar senhas, tal como as senhas de root e do user do banco de dados da aplicação. Inicialmente a plataforma gera uma sequência randômica alfanumérica de 16 caracteres, mas o usuário pode alterar este valor.
- PORT: Utilizada para informar ao autômato de deploy quais portas deverão ser expostas para a aplicação. Visando eliminar conflitos, a plataforma Embrapa I/O faz a gestão das portas atribuídas em cada cluster. Assim, ao selecionar uma variável deste tipo para a build será atribuído um valor entre 49152 e 65535, que é a faixa de portas válidas utilizada pela plataforma.
- VOLUME: Aqui o usuário poderá vincular um volume, configurado no passo anterior, a uma variável de ambiente.
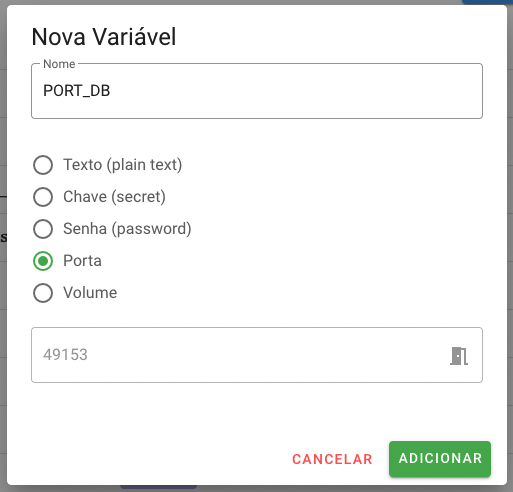
Passo 5: URLs
Quando é realizado o deploy da build, o autômato de deploy checa as portas válidas e as “expõe” publicamente no cluster. Assim, todas as variáveis do tipo PORT configuradas no passo anterior estarão acessíveis pelo domínio do cluster. Por exemplo, se o cluster escolhido for cluster.cnpgc.embrapa.br e no passo anterior o usuário tiver configurado as portas 55123 para uma aplicação Web e 55789 para conexão com o banco de dados MySQL, a aplicação na build estará disponível publicamente em http://cluster.cnpgc.embrapa.br:55123 e os usuários poderão acessar diretamente o banco de dados MySQL da aplicação por meio do host cluster.cnpgc.embrapa.br na porta 55789.
Atenção! Apesar de possível, não é indicado expor portas de serviços internos ao container, pois isto pode trazer riscos à segurança da aplicação.
Neste passo é possível atribuir à aplicação URLs mais “amigáveis”, com certificado SSL e semanticamente aderentes à sua finalidade. Há três formas de fazer isso:
-
Subdomínio Auto-Gerado: Todo cluster na plataforma Embrapa I/O possui, para cada estágio, uma coleção de domínios pré-configurados. Estes domínios têm por finalidade agregar valor semântico às URLs em que as aplicações são expostas. Por exemplo, no cluster
cluster.cnpgc.embrapa.brpoderíamos ter o subdomínioapi.cnpgc.embrapa.brpré-configurado. Caso esteja fazendo a configuração de uma aplicação denominada, por exemplo, “pasto-certo/backend”, que é a API do aplicativo Pasto Certo, o usuário poderia configurar uma URLhttps://pasto-certo.api.cnpgc.embrapa.brassociada à porta exposta na aplicação. É importante ressaltar que os subdomínios são configurados em cada cluster para cada estágio, então um subdomínio disponível para as builds em estágio de release não estará disponível para os demais estágios (alpha e beta). Os subdomínios são configurados pela equipe mantenedora do cluster. -
URL Externa (alias): Adicionalmente, é possível aos usuários configurarem seus próprios subdomínios em domínios de sua propriedade e apontá-los para as portas expostas da build. Para isso, basta ao usuário configurar um
CNAMEno DNS do domínio apontando para o hostrouter.embrapa.io. A plataforma irá então gerar os certificados SSL necessários e realizar as configurações para o roteamento do tráfego. Esta configuração é particularmente útil para vincular subdomínios da instituição, empresa ou Unidade da Embrapa em que atua aos apps criados na plataforma Embrapa I/O. Por exemplo, caso esteja na Embrapa Rondônia, poderia configurar no DNS um wildcard subdomain (registro do tipoA) com nome*.app.cpafro.embrapa.brapontando para o IP do servidor de roteamento (200.202.148.38). Agora, basta declarar neste campo um subdomínio com qualquer prefixo (p.e.,arbopasto.app.cpafro.embrapa.br) que a plataforma irá atribuir os certificados e realizar a configuraçãom de roteamento de tráfego de forma automática. -
Subpasta Auto-Gerada: Os subdomínios pré-conigurados no cluster podem ser utilizados também para mapear as portas das aplicações em subpastas (subpaths). Assim, como no exemplo acima, caso esteja fazendo a configuração de uma aplicação denominada “pasto-certo/backend”, que é a API do aplicativo Pasto Certo, o usuário poderia configurar uma URL
https://api.cnpgc.embrapa.br/pasto-certoassociada à porta exposta na aplicação.
Atenção! É necessário ter cuidado ao utilizar subpastas (subpaths), pois muitas vezes as aplicações referenciam recursos por meio de caminhos absolutos. Assim, a importação de um JS ou CSS a partir do “/”, por exemplo, não irá funcionar de forma automática, precisando ser configurado um
BASE_URL. Se possível, evite utilizar este tipo de URL par expor suas aplicações.
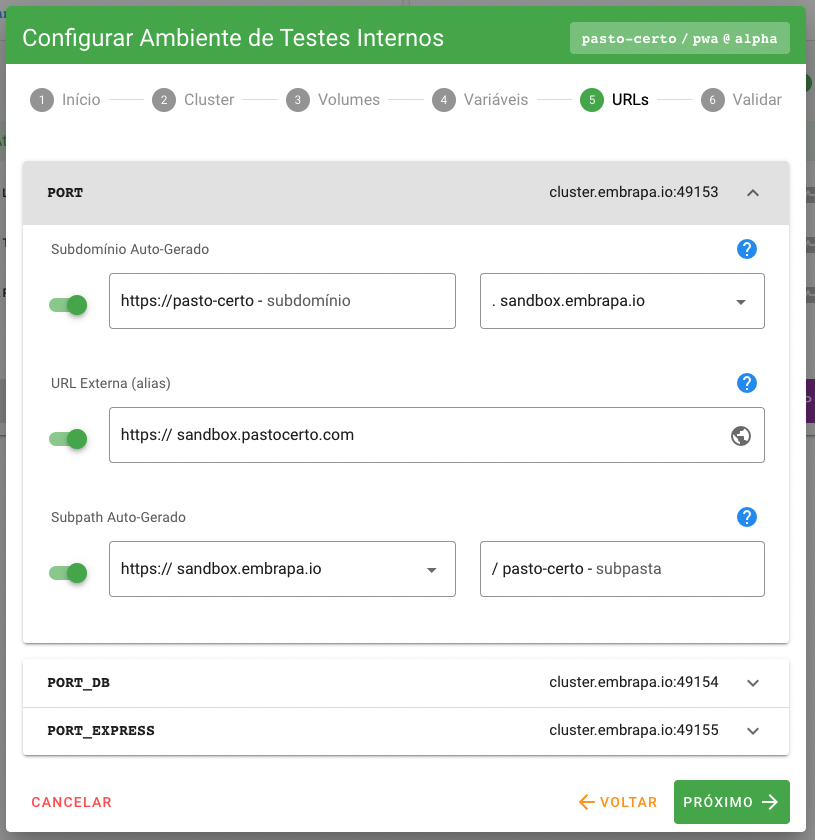
No exemplo acima, a aplicação que está implantada no cluster cluster.embrapa.io e exposta na porta 49153 estará disponível para acesso nas URLs:
- https://pasto-certo.sandbox.embrapa.io;
- https://sandbox.pastocerto.com; e
- https://sandbox.embrapa.io/pasto-certo.
Passo 6: Validate
No último passo o usuário deverá submeter as configurações da build para validação.
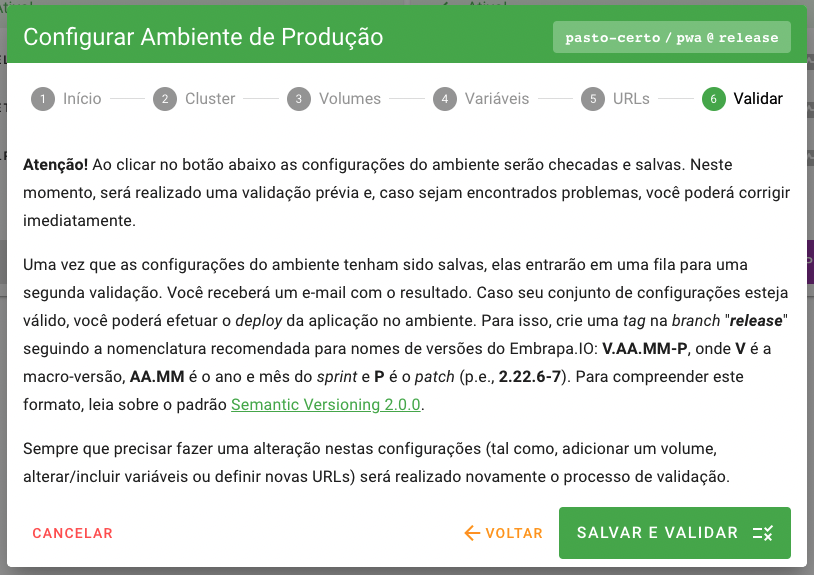
O processo de validação é realizado em duas etapas:
- Uma validação inicial é realizada no momento em que as configurações da build são enviadas, onde serão checados se todos os campos requeridos estão devidamente preenchidos; e
- Uma vez que a checagem inicial tenha sido bem sucedida, a build entra em uma fila para validação pelo autômato de deployer. Esta validação irá testar as configurações finais da build diretamente no orquestrador do cluster em que ela será instanciada. Caso tenha interesse, veja mais detalhes sobre os autômatos que compõem a plataforma no capítulo de arquitetura.
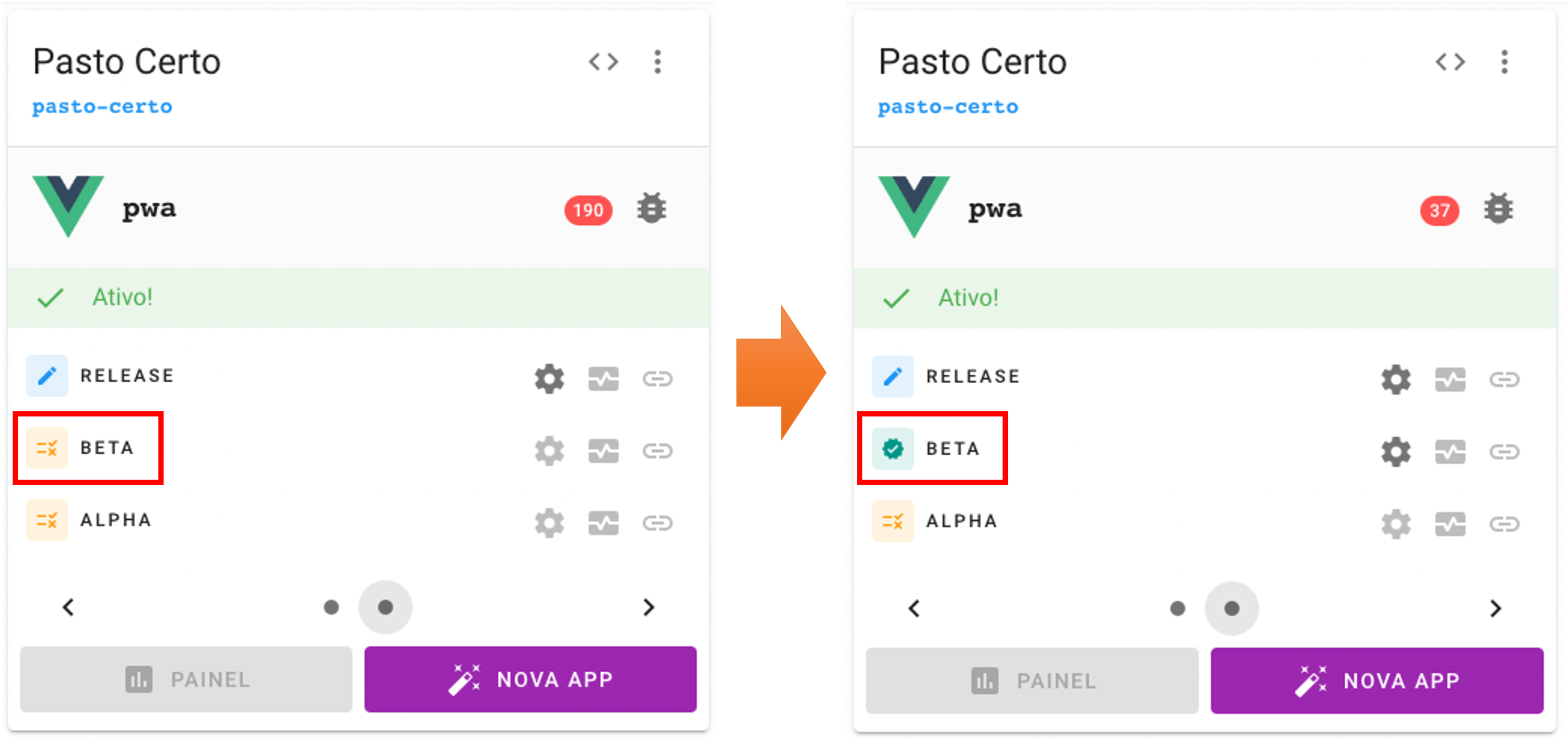
Quando o processo de validação da build for executado, será enviado um e-mail para a equipe do projeto com o log de execução:
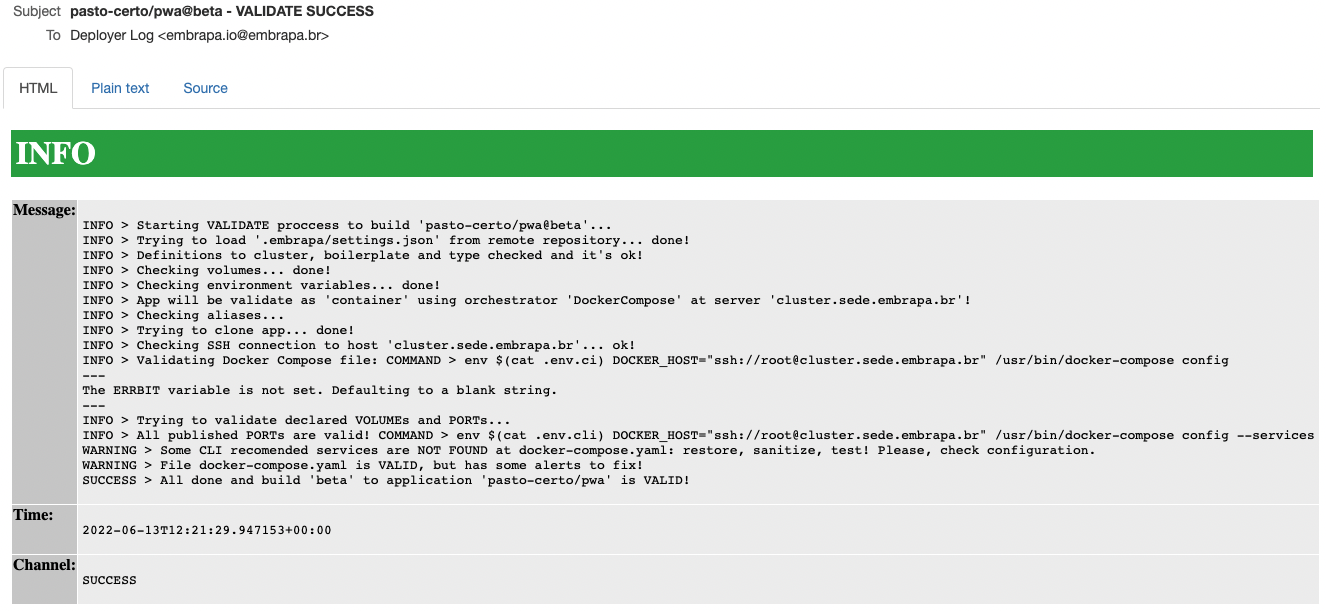
Uma vez que as configurações da build estejam plenamente validadas, já é possível realizar o seu deploy.