Conforme explicado no capítulo de arquitetura, o Embrapa I/O é uma plataforma do tipo Cloud Agnostic Architecture. Ou seja, se propõe a atuar com diferentes tecnologias de conteinerização e clusterização em nuvem, às quais são aqui chamadas de “orquestradores”.
Assim, é possível que uma aplicação, devidamente conteinerizada, seja instanciada em estágio alpha (para testes internos) em um orquestrador Docker Swarm rodando em um cluster de servidores localizado fisicamente na Embrapa Gado de Corte. A mesma aplicação poderia ser instanciada em estágio beta (para testes externos) em um orquestrador Kubernetes rodando em um cluster de servidores localizado fisicamente na Embrapa Agricultura Digital. Por fim, esta mesma aplicação poderia estar instanciada em estágio release (produção) em um orquestrador Cloud Foundry rodando na IBM Cloud.
Para possibilitar a “orquestração” dos ativos digitais nesta rede descentralizada de clusters, a plataforma implementa drivers de serviços. Estes drivers podem ser de dois tipos:
-
orquestrador: que efetua tarefas de validação dos stacks de containers, deploy/undeploy, health check, backup, sanitização, etc; e
-
storer: que instancia volumes no próprio cluster ou em servidores externos do tipo storage.
O provisionamento de novos clusters, storages e o desenvolvimento de drivers, estão alinhados com a estratégia de desenvolvimento colaborativo e manutenção compartilhada da plataforma. Assim, da mesma forma que ocorre com os boilerplates, clusters são mantidos por equipes descentralizadas, que podem ser internas ou externas à Embrapa.
Desta forma, unidades descentralizadas, instituições e empresas parceiras da Embrapa podem compor a rede de clusters do Embrapa I/O, integrando servidores reais ou VMs de seus próprios CPDs. Com isso, a gestão das aplicações nestes servidores físicos ou máquinas virtuais passa a ser realizada pelos processos de DevOps da plataforma.
Atenção! Os processos automatizados de backup nos clusters são de atribuição da equipe de mantenedores, sendo que o Embrapa I/O aborda apenas o backup sob demanda, já detalhado anteriormente. Da mesma forma, recursos essenciais adicionais, tal como envio de e-mail (SMTP) devem ser disponibilizados na rede interna em que o servidor está instalado e devidamente informado na documentação do cluster.
Passo-a-Passo de Configuração
A seguir são listados os passos básicos para disponibilização do cluster.
- Instalação do orquestrador (com Docker Compose ou Docker Swarm);
- Integração (via SSH) do cluster ao Embrapa I/O;
- Liberação das demais portas no firewall;
- Configuração do plugin para logging;
- Ativação do Web Terminal (opcional);
- Instalação de um Distribution Registry (opcional); e
- Configuração do Portainer (opcional).
1. Instalação do orquestrador
Neste primeiro passo será abordado o provisionamento básico do(s) servidor(es) - físico(s) ou virtual(is) - do cluster, tal como a instalação do sistema operacional sugerido, o orquestrador e storer associado.
Docker Compose
Para instalação do orquestrador em Docker Compose é necessário disponibilizar um único servidor dedicado (bare metal) ou máquina virtual. É recomendado o uso da distribuição Linux Ubuntu Server 24.04 LTS. É necessário que seja utilizada a arquitetura amd64. No momento da instalação do SO, haverá a possibilidade de instalar pacotes adicionais. Neste momento, selecione o SSH Server.
Uma vez que o shell esteja disponível, atualize completamente a distribuição (apt update && apt upgrade -y && apt dist-upgrade -y && apt autoremove -y && apt autoclean) e proceda com o passo-a-passo oficial para instalação do Docker.
Atenção! Após concluir da instalação, é fortemente recomendado efetuar o login no Docker utilizando uma conta institucional. O uso do Docker não-autenticado pode resultar em erros durante o processo de deploy (p.e.,
Temporary failure in name resolution).
Agora será necessário configurar um storer associado ao cluster, que é o servidor físico onde serão armazenados os volumes utilizados pelos containers para persistir dados:
-
DockerLocal: Caso não haja uma outra VM ou um outro servidor do tipo storage disponível, que seria o equipamento mais apropriado, é possível configurar um storer local. Na prática será um diretório no próprio cluster onde todos os volumes serão criados fisicamente. Para isto, basta criar um diretório em qualquer local no servidor e atribuir permissões de escrita. -
DockerNFSv4: Havendo uma outra VM ou outro servidor físico de storage disponível, os mantenedores poderão instalar e/ou habilitar o NFS (versão 4) nele. É importante que no arquivo/etc/exportssejam parametrizados, pelo menos, as seguintes opções no diretório a ser montado:rw,no_root_squash,sync,no_subtree_checkeinsecure.
É fortemente recomendado ajustar alguns parâmetros do Linux (sysctl). Normalmente estes parâmetros são ajustados editando o arquivo /etc/sysctl.d/99-sysctl.conf (ou diretamente o /etc/sysctl.conf em distribuições mais antigas). Considere os seguintes parâmetros e correspondentes valores mínimos:
fs.file-max=2000000
kernel.pid_max=128000
kernel.threads-max=128000
vm.max_map_count=524288
Docker Swarm
Para instalação do orquestrador em Docker Swarm é necessário disponibilizar três ou mais servidores dedicados (bare metal) ou máquinas virtuais. Em cada uma delas deverá ser instalado, preferencialmente, a distribuição Linux Ubuntu Server 24.04 LTS. É necessário que seja utilizada a arquitetura amd64. No momento da instalação do SO, haverá a possibilidade de instalar pacotes adicionais. Neste momento, selecione o SSH Server.
Uma vez que o shell esteja disponível, atualize completamente a distribuição (apt update && apt upgrade -y && apt dist-upgrade -y && apt autoremove -y && apt autoclean) em cada um dos nós e proceda com o passo-a-passo oficial para instalação do Docker.
Atenção! Após concluir da instalação, é fortemente recomendado efetuar o login no Docker utilizando uma conta institucional (pelo menos nos nós do tipo manager). O uso do Docker não-autenticado pode resultar em erros durante o processo de deploy (p.e.,
Temporary failure in name resolution).
Para instalar o Docker Swarm, siga os passos da documentação oficial. Você deverá definir a quantidade de servidores que atuará como manager nodes e como worker nodes. Considere a orientação da documentação oficial para otimizar a tolerância à falhas, onde o número de managers deverá ser sempre ímpar. Assim, caso tenha 4 servidores/VMs em seu cluster, considere criar 3 manager nodes e 1 worker node. Por fim, adicione todos os nós ao swarm.
Todo cluster Docker Swarm deverá possuir um servidor para registro de imagens (Docker Registry) rodando localmente na porta padrão. Ele será utilizado para registrar as imagens criadas no build em tempo de deploy das aplicações. Para criá-lo no swarm, faça:
docker service create --name registry --publish published=5000,target=5000 registry:3
Configure agora um storer associado ao cluster, que é o servidor físico onde serão armazenados os volumes utilizados pelos containers para persistir dados:
SwarmNFSv4: Será necessário ter um servidor de storage dedicado ao cluster em Docker Swarm. Nele, os mantenedores deverão instalar e/ou habilitar o NFS (versão 4). É importante que no arquivo/etc/exportssejam parametrizados, pelo menos, as seguintes opções no diretório a ser montado:rw,no_root_squash,sync,no_subtree_checkeinsecure. Todos os nós do cluster devem ser capazes de montar o storage NFS.
2. Integração (via SSH) do cluster à plataforma
Para realizar a integração do novo cluster com a plataforma Embrapa I/O, os mantenedores deverão configurar nas máquinas (todos os nós do cluster e o storage, caso exista), reais ou virtuais, um usuário e a chave única de acesso SSH.
Atenção! Nos comandos abaixo o
sudofoi omitido, mas talvez você precise adicioná-lo no início das sentenças para executá-los de forma apropriada.
a. Criação do usuário exclusivo:
Você deverá criar um usuário que será utilizado exclusivamente para executar os pipelines de DevOps do Embrapa I/O neste cluster. O usuário pode ter qualquer username, porém, para exemplificar, utilizaremos o login “io”:
adduser --disabled-login --gecos "" --shell /bin/bash io
Nos clusters, ou seja, as máquinas em que o Docker estiver executando (tal como todos os nós de um orquestrador Docker Swarm), adicione este usuário ao grupo apropriado:
usermod -aG docker io
Com isso o usuário terá as permissões necessárias para executar os comandos do Docker.
b. Adição do usuário ao sudoers:
Caso seu cluster esteja utilizando um storage desacoplado, execute os comandos abaixo apenas neste storage. Caso o armazenamento de volumes seja local, ou seja, no próprio cluster, execute os comando abaixo nele.
As instruções criam os diretórios em que os volumes serão armazenados e concede ao usuário de DevOps a permissão de alterar o proprietário e permissões de suas subpastas. Para exemplificar, foi considerado que o diretório de armazenamento de volumes será o /mnt/nfs e que o usuário de DevOps tem o login “io”:
mkdir /mnt/nfs && chown io:io /mnt/nfs && chmod 700 /mnt/nfs
echo "io ALL=(ALL) NOPASSWD: /bin/chown * /mnt/nfs/*, /bin/chmod * /mnt/nfs/*" > /etc/sudoers.d/io
c. Configuração da chave SSH:
Adicione agora a seguinte chave pública SSH no arquivo .ssh/authorized_keys do usuário:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAACAQCykAvX7CZmqw1bgOCOmRtgpfr55cjqO0v1+DImp4pKrITdFxZu0OqsJgHjio/yp4w5+KvWmFJa5woYbZry9inFciwKo3+rpGjBHJfNfDq70/q3VdSSInFrSMtWgBk0x5QZQ78ENkNkO9DRIdnnffN9bY1uibR6ZX0pCSSyTGgx3NlAakW47tYIzVcrrUGKGG8vZwSkl7GhEEXtNETp02WQpkUvYrNqgRrmw2lvv41QfRETIuNN7PDhJrDO4tYHtix5D+Pvd05IacgTVQxpi6vnMVdgrwbZ1RPw9TLLkoy3kZs45hLG9oipiYOiD6rxiIYC0f1iUaKz9PKZdfnF8Ya5XJFoL6NcBTPDGh01dkEBonOWt3lgpC/2SBM/SeClt8M2lI6KtqAkjPEKWhnirDP0lXzY2CYamnu2rD6p4z4OWAYG6ngQcCIK45vQvsSz8mfitWnJe89WCCaEVj+L1QO/hjnKJ+eKf5ze35HagFRhpIAB34FmGHO3N8yFCLqvHFNLw6dKl5IXU2cvJF1jwhL3coOx9oeFZLPk45Zze2e/Itjd9x84gWtmo60MvXVBsYGYlcZLzSgAbNGldMuxAFWs0ZvghNx+KZjg6fZ2hAlPHIg1MiAlztyLbbjV2Mjc6ke6sjBDvPkPZQde6G/T8Mp56cCtAb/77/dw78zruX5qyQ== embrapa.io
Por exemplo, considerando que foi criado um usuário com login “io” e que a chave acima está na variável $PUBLIC_KEY, faça (em todos os nós do cluster e no storage, caso exista):
mkdir -p /home/io/.ssh && chmod 700 /home/io/.ssh
echo "$PUBLIC_KEY" > /home/io/.ssh/authorized_keys
chmod 600 /home/io/.ssh/authorized_keys && chown -R io:io /home/io/.ssh
Além de autorizar a chave, assegure que o firewall permita o acesso do host core.embrapa.io (IP 200.202.148.38) em cada uma das máquinas (inclusive o storage, caso exista) via SSH na porta 22.
Atenção! Neste momento não é possível ainda alterar a porta do SSH. Esta configuração simples tem implicações profundas no Docker CLI e na forma como ele está integrado à plataforma Embrapa I/O.
Repare que, com esta configuração, os autômatos do Embrapa I/O conseguirão acessar os servidores do cluster. Isso é necessário para que a plataforma consiga provisionar no servidor todos os artefatos para deploy das aplicações (tal como diretórios, networks e volumes, além de realizar a build e instanciação das imagens e containers).
3. Liberação das demais portas no firewall
O Embrapa I/O expõe as aplicações instanciadas em portas na faixa de 49152 a 65535. Portanto, toda esta faixa de portas deverá ser exposta para acesso público nos servidores de aplicação que compõem o cluster (p.e., todos os nós managers e workers no Docker Swarm).
Atenção! Existe um limite de 30 projetos para cada cada cluster do Embrapa I/O. Este limite está relacionado ao limite padrão do Docker, onde um único host não deve possuir mais do que 30 networks. É possível contornar esta limitação, mas visando manter uma complexidade comedida da gestão das VMs, sugere-se mantê-lo. É importante frisar que o número de aplicações em cada projeto e de containers em cada aplicação não é limitado pela plataforma e, portanto, ficará a cargo das limitações de hardware, sistema operacional e outros recursos escassos, tal como a quantidade máxima de portas expostas em cada cluster (no caso, 16.383).
4. Configuração do plugin para logging
O Embrapa I/O utiliza o Grafana Loki para permitir a coleta e análise de log de todos os containers instanciados. Assim, é necessário instalar o plugin do Loki para que toda a saída dos containers (no stdout) seja enviada para o Grafana.
Para instalar o plugin, execute:
docker plugin install grafana/loki-docker-driver:latest --alias loki --grant-all-permissions
Verifique a instalação utilizando o comando docker plugin ls.
Uma vez que o plugin esteja instalado no Docker, edite o arquivo /etc/docker/daemon.json (ou /var/snap/docker/current/config/daemon.json, se tiver sido instalado pelo Snap) inserindo o seguinte conteúdo:
{
"debug" : true,
"log-driver": "loki",
"log-opts": {
"loki-url": "https://<username>:<password>@loki.embrapa.io/loki/api/v1/push",
"loki-batch-size": "400",
"loki-retries": "5",
"loki-max-backoff": "1s",
"loki-timeout": "2s",
"keep-file": "true"
}
}
Atenção! Os valores de
usernameepasswordpara a linha acima devem ser obtidos junto à Supervisão de Desenvolvimento de Ativos Digitais (DEGI/GCI/GTI/SDAD).
Por fim, faça: systemctl restart [service], onde [service] pode ser docker ou snap.docker.dockerd (se tiver sido instalado via Snap). Caso tenha dúvida sobre o nome exato do serviço, execute systemctl list-units --type=service | grep docker. É possível verificar se há algum erro utilizando o comando journalctl -u [service] | grep loki. Se configurado com sucesso, deverá ser visto na saída deste último comando algo como “Using default logging driver loki”.
5. Ativação do Web Terminal (opcional)
O recurso de Web Terminal permite que membros do projeto com o papel de Arquitetos da Solução acessem diretamente o shell dos containers das aplicações (via ash, bash, dash ou sh). Este recurso é útil para depurar, realizar manutenções eventuais e fazer intervenções pontuais no container em execução.
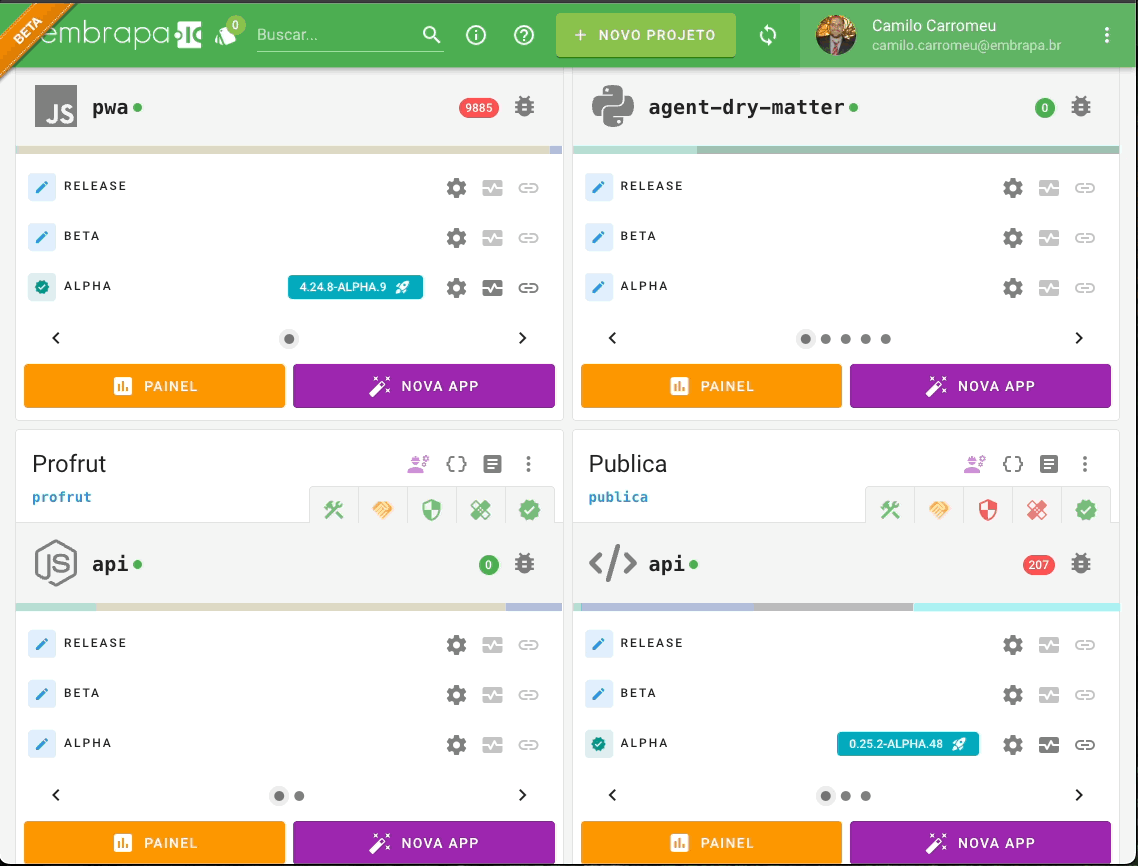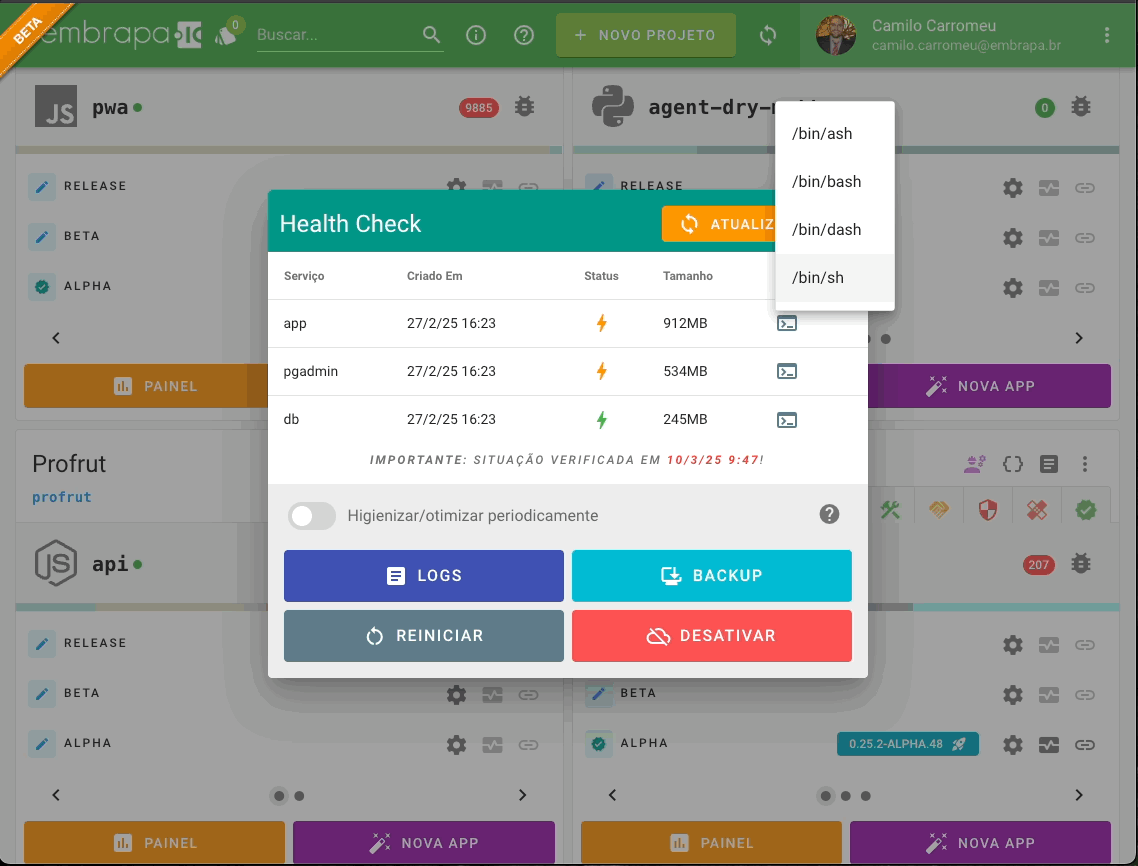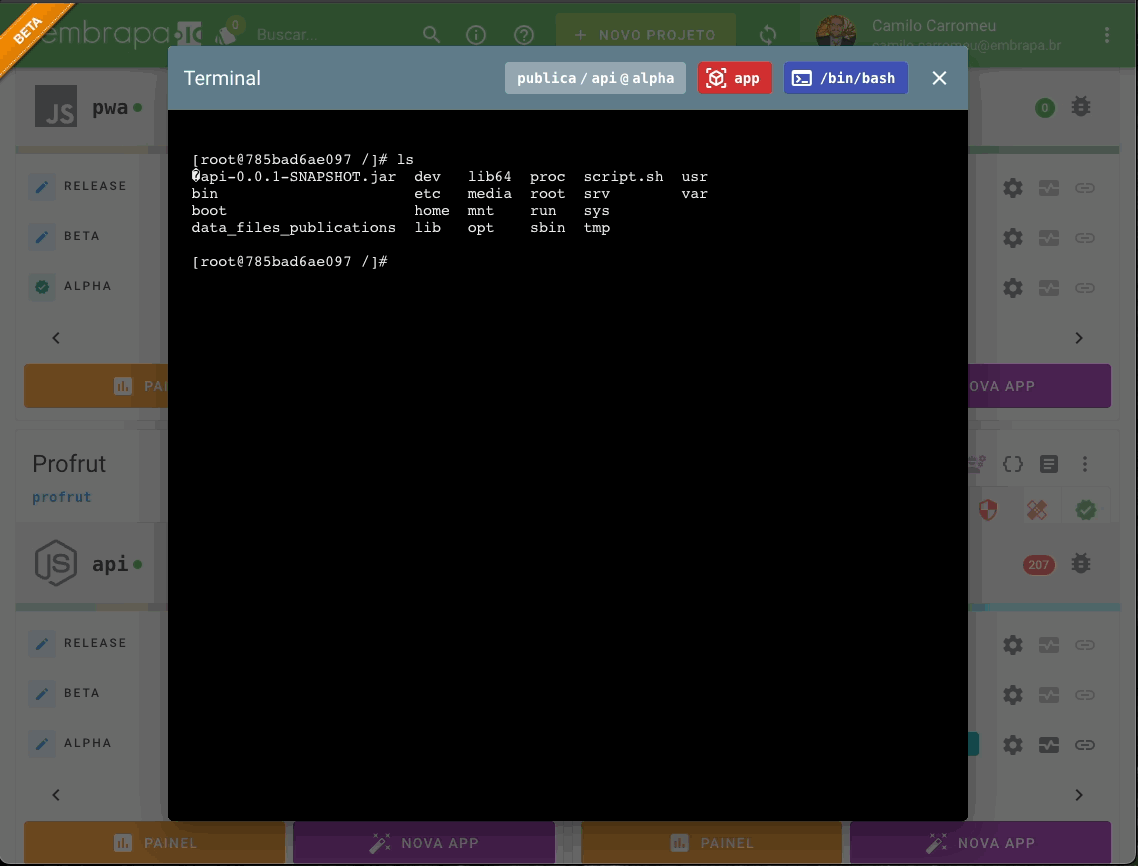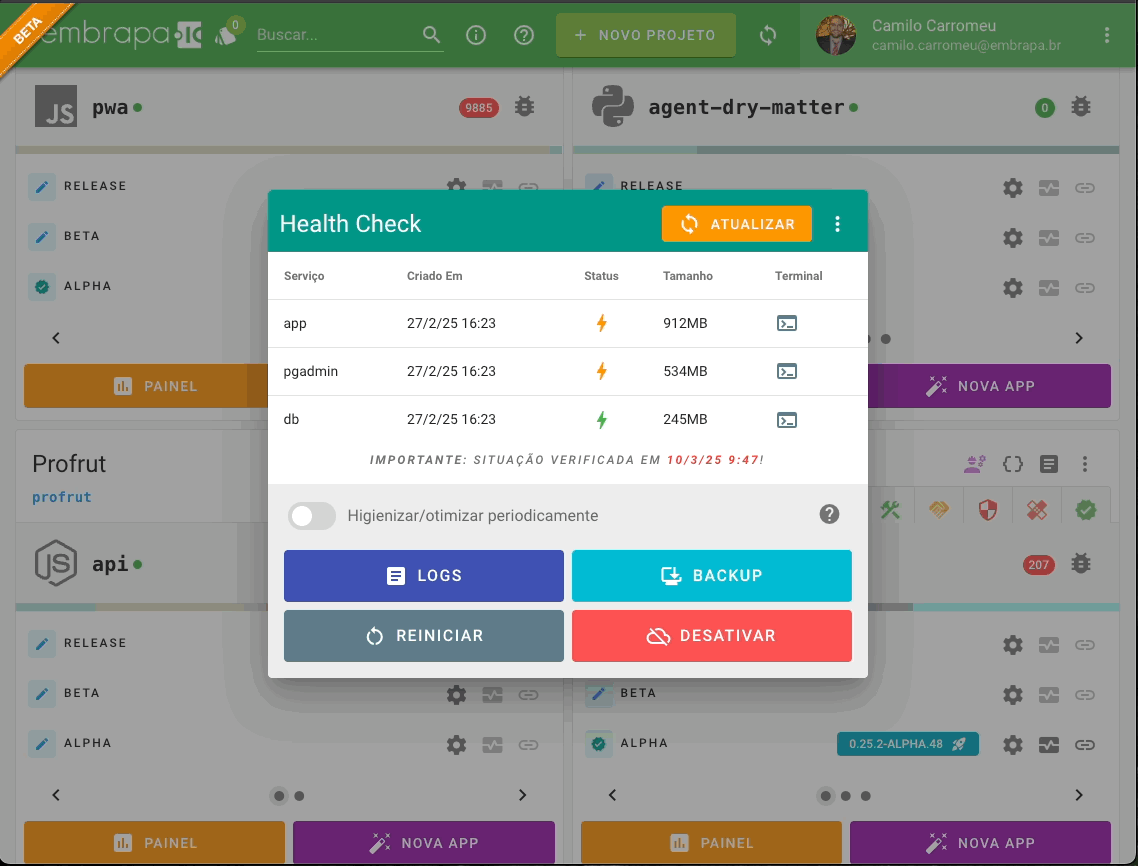
A ativação do Web Terminal é um recurso opcional, que a equipe de mantenedores do cluster pode ativar ou não (assim como, p.e., a disponibilização de um SMTP para envio de e-mails). Para ativação do recurso no cluster é necessário ter um utilitário instalado que foi desenvolvido especificamente para esta finalidade.
Para instalá-lo, sugere-se a criação de um script denominado /root/terminal.sh com o seguinte conteúdo…
…no Docker Compose:
#!/bin/sh
type docker > /dev/null 2>&1 || { echo >&2 "Command 'docker' has not been found! Aborting."; exit 1; }
set -x
set +e
docker stop terminal
docker rm terminal
set -e
docker pull embrapa/terminal
docker run --name terminal \
-v /var/embrapa/ssl/wildcard/cnpxx.crt:/ssl/server.crt:ro \
-v /var/embrapa/ssl/wildcard/cnpxx.key:/ssl/server.key:ro \
-v /var/run/docker.sock:/var/run/docker.sock:ro \
-p 65500:5000 \
--restart unless-stopped -d \
embrapa/terminal
…no Docker Swarm:
#!/bin/sh
type docker > /dev/null 2>&1 || { echo >&2 "Command 'docker' has not been found! Aborting."; exit 1; }
set -x
set +e
docker service rm terminal
set -e
docker pull embrapa/terminal
docker service create --name terminal \
--mode=global \
--mount=type=bind,src=/var/embrapa/ssl/wildcard/cnpxx.crt,dst=/ssl/server.crt,readonly \
--mount=type=bind,src=/var/embrapa/ssl/wildcard/cnpxx.key,dst=/ssl/server.key,readonly \
--mount=type=bind,src=/var/run/docker.sock,dst=/var/run/docker.sock,readonly \
--publish published=65500,target=5000 \
embrapa/terminal
Repare que os caminhos para os certificados SSL (cnpxx.crt e cnpxx.key) devem ser alterados para corresponder aos corretos.
Em seguida, atribua permissões (chmod +x /root/terminal.sh) e execute. Ao finalizar, para verificar se está tudo certo, dê o comando…
…no Docker Compose:
docker logs -f terminal
…no Docker Swarm:
docker logs -f $(docker ps -q -f name=terminal)
Você deverá ver a mensagem “WebSocket Server running!”.
6. Instalação de um Distribution Registry (opcional)
Como vimos acima, a instalação de um Distribution Registry local é obrigatória caso esteja utilizando como orquestrador o Docker Swarm. Caso contrário, ela é opcional. Porém, mesmo nestes casos, pode ser útil ter um registry local para armazenar as imagens dos seus builds e, desta forma, prover mais agilidade e segurança nos processos de deploy.
Para instalar, basta executar o comando:
docker run -d -p 5000:5000 --name registry registry:3
Atenção! Este registro deverá ser utilizado apenas localmente e, portanto, a porta 5000 não deverá ser exposta publicamente no firewall.
7. Configuração do Portainer (opcional)
Adicionalmente, é fortemente recomendado que seja instalado o Portainer para auxiliar a equipe mantenedora de clusters em Docker Compose, Docker Swarm ou Kubernetes em sua gestão. Por padrão, recomenda-se que este seja disponibilizado publicamente no HTTPS (porta 443) da URL do cluster, com o HTTP (porta 80) redirecionando para o HTTPS. Desta forma, será necessário abrir também em seu firewall o acesso às portas 80 e 443 do novo cluster (além das portas altas comentadas acima).
Para simplificar a instalação e recorrente atualização do Portainer (quando necessário), crie um script denominado /root/portainer.sh com as seguintes instruções:
#!/bin/sh
type docker > /dev/null 2>&1 || { echo >&2 "Command 'docker' has not found! Aborting."; exit 1; }
set -x
set +e
docker stop portainer
docker rm portainer
docker volume create portainer_data
set -e
docker pull portainer/portainer-ce:latest
docker run -d -p 8000:8000 -p 9443:9000 --name portainer --restart=always -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainer-ce:latest
Além disso, instale o Nginx e, para a configuração acima do Portainer, especifique um novo site como segue (troque io.cnpxx.embrapa.br pelo nome correto do seu cluster):
server {
listen 80;
listen [::]:80;
server_name io.cnpxx.embrapa.br;
return 301 https://io.cnpxx.embrapa.br;
}
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
ssl_certificate /etc/embrapa/wildcard/io.cnpxx.embrapa.br/fullchain.pem;
ssl_certificate_key /etc/embrapa/wildcard/io.cnpxx.embrapa.br/privkey.pem;
ssl_trusted_certificate /etc/embrapa/wildcard/io.cnpxx.embrapa.br/fullchain.pem;
ssl_protocols TLSv1.2 TLSv1.3;
server_name io.cnpxx.embrapa.br;
location / {
resolver 127.0.0.1 [::1];
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header Access-Control-Allow-Origin '*';
proxy_set_header Access-Control-Allow-Methods 'GET, POST, OPTIONS, PUT, DELETE, HEAD';
proxy_cache_bypass $http_upgrade;
proxy_ssl_session_reuse off;
proxy_pass https://localhost:9443;
}
}
8. Backup e limpeza do cache (opcional)
Para backup periódico do cluster, além dos processos e protocolos existentes no data center em que está alocado, recomenda-se configurar um schedular job diário utilizando a ferramenta docker-backup. Uma vez instalada e devidamente adicionada ao path do sistema operacional, crie um arquivo .sh com o seguinte conteúdo:
#!/bin/sh
HOSTNAME=$(hostname)
echo "Starting embrapa.io backup process to $HOSTNAME..."
type docker > /dev/null 2>&1 || { echo >&2 "Command 'docker' has not found! Aborting."; exit 1; }
type docker-backup > /dev/null 2>&1 || { echo >&2 "Command 'docker-backup' has not found! See: https://github.com/muesli/docker-backup. Aborting."; exit 1; }
set -e
BKP_PATH="/var/opt/embrapa.io/backup"
mkdir -p $BKP_PATH
[ ! -d $BKP_PATH ] && echo "$BKP_PATH does not exist." && exit 1
BKP_FOLDER="io_cluster_$(date +%Y-%m-%d_%H-%M-%S)"
echo "Deleting old backups (older than 7 days)..."
find $BKP_PATH -type f -name "*.tar.gz" -mtime +7 -exec rm {} \;
echo "Creating backup folder: '$BKP_FOLDER'..."
mkdir -p $BKP_PATH/$BKP_FOLDER/$HOSTNAME
set +e
echo "Starting Docker backup process with 'docker-backup' to all containers..."
cd $BKP_PATH/$BKP_FOLDER/$HOSTNAME
docker-backup backup --all --stopped --tar --verbose
set -e
echo "Compressing backup folder..."
cd /tmp
tar -czvf $BKP_PATH/$BKP_FOLDER.tar.gz -C $BKP_PATH $BKP_FOLDER
rm -rf $BKP_PATH/$BKP_FOLDER
echo "All done! Backup file at: $BKP_PATH/$BKP_FOLDER.tar.gz"
echo "Clean up unused images..."
docker builder prune -af --filter "until=24h"
docker image prune -af --filter "until=24h"
Adicione este arquivo no CRON para ser executado diariamente. Por exemplo, se foi criado um arquivo /root/embrapa.io/backup/cluster.sh, crie um script /etc/cron.daily/io com o seguinte conteúdo:
#!/bin/sh
find /var/log -type f -name "embrapa.io*" -mtime +14 -exec rm {} \;
DATE="$(date +%Y-%m-%d)"
/root/embrapa.io/backup/cluster.sh >> /var/log/embrapa.io-cluster-$DATE.log 2>&1
Em seguida, faça:
chmod +x /root/embrapa.io/backup/cluster.sh
chmod +x /etc/cron.daily/io
/etc/init.d/cron reload
É importante notar as linhas finais do script de backup, onde aparecem os comandos:
echo "Clean up unused images..."
docker builder prune -af --filter "until=24h"
docker image prune -af --filter "until=24h"
O processo de build do Docker gera uma imensa quantidade de imagens e outros arquivos de cache. Isto tende a ocupar rapidamente todo o espaço em disco. Estes comandos garantem que este cache não tenha mais do que 24 horas.
Atenção! Ainda que opte por não configurar o processo de backup sugerido acima, considere criar um schedular job para executar as linhas de limpeza do cache diariamente.
Disponibilizando no Catálogo
Uma vez configurado o cluster, basta montar as configurações em formato JSON e enviar para a equipe de gestão da plataforma. O exemplo abaixo demonstra como deverão ser as configurações:
{
"release": [
{
"host": "io.facom.ufms.br",
"ssh":{
"user": "devops"
},
"network": {
"subnet": "172.30.0.0"
},
"local": "Faculdade de Computação da UFMS",
"location": "Campo Grande - MS",
"orchestrator": "DockerCompose",
"storage": {
"type": "DockerNFSv4",
"host": "storage.facom.ufms.br",
"path": "/mnt/nfs"
},
"aliases": [
"releases.facom.ufms.br",
"agro.facom.ufms.br",
"farm.facom.ufms.br",
"live.facom.ufms.br",
],
"disabled": false,
"maintainers": [
{ "name": "Hercule Poirot", "email": "hercule.poirot@ufms.br", "phone": "+55 (67) 9 8888-7777" },
{ "name": "Maria Capitolina Santiago", "email": "capitu.santiago@ufms.br", "phone": "+55 (67) 9 6666-5555" }
],
"resources": {
"smtp": {
"active": true,
"host": "smtp.facom.ufms.br",
"port": 25,
"tls": false
},
"terminal": {
"active": true,
"port": 65500
},
"external": {
"active": true
},
"registry": {
"active": false
},
"backup": {
"active": true
},
"snapshot": {
"active": true
}
}
},
{
"host": "cluster.cnpgc.embrapa.br",
"ssh":{
"user": "io"
},
"nodes": {
"manager": [
"manager1.cnpgc.embrapa.br",
"manager2.cnpgc.embrapa.br"
],
"worker": [
"worker1.cnpgc.embrapa.br"
]
},
"local": "Embrapa Gado de Corte",
"location": "Campo Grande - MS",
"orchestrator": "DockerSwarm",
"storage": {
"type": "SwarmNFSv4",
"host": "storage.cnpgc.embrapa.br",
"path": "/swarm"
},
"aliases": [
"app.cnpgc.embrapa.br",
"manager.cnpgc.embrapa.br",
"api.cnpgc.embrapa.br",
"portal.cnpgc.embrapa.br"
],
"disabled": false,
"maintainers": [
{ "name": "Dorothy Gale", "email": "dorothy.gale@embrapa.br", "phone": "+55 (67) 3368-1122" },
{ "name": "Bras Cubas", "email": "bras.cubas@embrapa.br", "phone": "+55 (67) 3368-3344" },
{ "name": "Tyler Durden", "email": "tyler.durden@embrapa.br", "phone": "+55 (67) 3368-5566" }
],
"resources": {
"smtp": {
"active": true,
"host": "smtp.cnpgc.embrapa.br",
"port": 587,
"tls": true
},
"terminal": {
"active": false,
"port": 65500
},
"external": {
"active": false
},
"registry": {
"active": true
},
"backup": {
"active": true
},
"snapshot": {
"active": true
}
}
}
],
"beta": [
{
"host": "io.facom.ufms.br",
"ssh":{
"user": "devops"
},
"network": {
"subnet": "172.29.0.0"
},
"local": "Faculdade de Computação da UFMS",
"location": "Campo Grande - MS",
"orchestrator": "DockerCompose",
"storage": {
"type": "DockerNFSv4",
"host": "storage.facom.ufms.br",
"path": "/mnt/nfs"
},
"aliases": [
"test.facom.ufms.br",
"beta.facom.ufms.br"
],
"disabled": false,
"maintainers": [
{ "name": "Hercule Poirot", "email": "hercule.poirot@ufms.br", "phone": "+55 (67) 9 8888-7777" },
{ "name": "Maria Capitolina Santiago", "email": "capitu.santiago@ufms.br", "phone": "+55 (67) 9 6666-5555" }
],
"resources": {
"smtp": {
"active": true,
"host": "smtp.facom.ufms.br",
"port": 25,
"tls": false
},
"terminal": {
"active": true,
"port": 65500
},
"external": {
"active": true
},
"registry": {
"active": false
},
"backup": {
"active": false
},
"snapshot": {
"active": true
}
}
}
],
"alpha": [
{
"host": "io.facom.ufms.br",
"ssh":{
"user": "devops"
},
"network": {
"subnet": "172.28.0.0"
},
"local": "Faculdade de Computação da UFMS",
"location": "Campo Grande - MS",
"orchestrator": "DockerCompose",
"storage": {
"type": "DockerLocal",
"path": "/mnt/volumes"
},
"aliases": [
"sandbox.facom.ufms.br",
"alpha.facom.ufms.br"
],
"disabled": false,
"maintainers": [
{ "name": "Hercule Poirot", "email": "hercule.poirot@ufms.br", "phone": "+55 (67) 9 8888-7777" },
{ "name": "Elizabeth Bennet", "email": "elizabeth.bennet@ufms.br", "phone": "+55 (67) 9 4444-3333" },
{ "name": "Fitzwilliam Darcy", "email": "fitzwilliam.darcy@ufms.br", "phone": "+55 (67) 9 2222-1111" }
],
"resources": {
"smtp": {
"active": true,
"host": "smtp.facom.ufms.br",
"port": 25,
"tls": false
},
"terminal": {
"active": true,
"port": 65500
},
"external": {
"active": true
},
"registry": {
"active": false
},
"backup": {
"active": false
},
"snapshot": {
"active": true
}
}
}
]
Repare que o cluster deve ser configurado especificamente para cada estágio da aplicação. Assim, ele pode estar disponível para os estágios alpha, beta e/ou release, ou seja, não necessariamente para todos. O host deverá apontar para o IP real do servidor ou VM. O atributo ssh.user permite especificar o usuário exclusivo para acionar os processos de deploy no cluster. Já os atributos local e location indicam a Unidade da Embrapa, instituição ou empresa e a sua localização geográfica.
Para evitar conflitos com outros hosts na rede do data center que abriga as máquinas do cluster, é possível especificar em qual subnet interna (faixa de IPs) o orquestrador irá alocar as redes (do tipo bridge) das stacks de containers. Repare que nas configurações do cluster io.facom.ufms.br as subnets estão definidas. Para cada estágio em que a subnet for configurada, será permitido sempre o provisionamento de 255 stacks (ou seja, para o estágio alpha no exemplo acima, será de 172.28.1.0/24 até 172.28.255.0/24). Em cada stack, por sua vez, será permitida a alocação de 256 IPs (CIDR /24). Na prática, cada serviço da stack de containers recebe um destes IPs. É possível verificar se uma subnet está vaga no host com o comando ip route show e em todo o data center por meio do comando nmap (para a faixa de IPs do exemplo, o comando preciso seria nmap -sn 172.28.0.0/16). Normalmente as subnets na faixa de 172.19.0.0/16 a 172.31.0.0/16 são escolhas práticas seguras para as redes dos containers.
O orchestrator indica o driver de orquestração que está sendo utilizado. No exemplo acima, o cluster io.facom.ufms.br está configurado com o orquestrador Docker Compose e, portanto, é composto por um único servidor para deploy dos containers. Já o cluster cluster.cnpgc.embrapa.br está configurado com o orquestrador Docker Swarm e é, portanto, composto por diversos nós. Neste caso, no atributo host deverá ser referenciado um manager node principal, que no nosso exemplo é o cluster. No atributo node estão declarados explicitamente os demais nós, sendo manager1 e manager2 como manager nodes e worker1 como um worker node, totalizando assim os 4 (quatro) nós que formam este cluster.
O atributo storage contém o driver de storer e atributos relacionados. Por exemplo, para o estágio alpha foi configurado um storer utilizando o driver DockerLocal e, desta forma, os volumes serão criados no diretório /mnt/volumes indicado no atributo path. Já em estágio beta e release está sendo utilizado o driver para NFSv4 e, desta forma, os volumes serão criados fisicamente no diretório remoto /mnt/nfs do storage storage.facom.ufms.br.
Os aliases são subdomínios configurados pela Unidade da Embrapa, instituição ou empresa parceira que possibilitam alocar as aplicações em domínios mais condizentes semanticamente com a sua finalidade. Estes aliases devem ser configurados no DNS da seguinte forma:
- Para cada alias, crie um registro do tipo
CNAMEapontando pararouter.embrapa.io; e - Para cada alias, crie um wildcard subdomain (registro do tipo
A) apontando para o IP dorouter.embrapa.io(ou seja,200.202.148.38).
Assim, para um alias app.cnpgc.embrapa.br, teríamos:
Name Type Value
---------------------- ----- -----------------
app.cnpgc.embrapa.br CNAME router.embrapa.io
*.app.cnpgc.embrapa.br A 200.202.148.38
Vale ressaltar que as aplicações instanciadas estarão sempre expostas por meio das portas atribuídas a elas em cada cluster. Em clusters com múltiplos nós (nodes), as réplicas em cada nó poderão ser acessadas de forma distinta pelo endereço real do nó e porta específica. O load balancer será automaticamente ativado quando um alias, URL externa ou subpath for configurado. Para isso, é utilizado o método least connected do Nginx, onde a próxima solicitação é atribuída ao servidor com o menor número de conexões ativas.
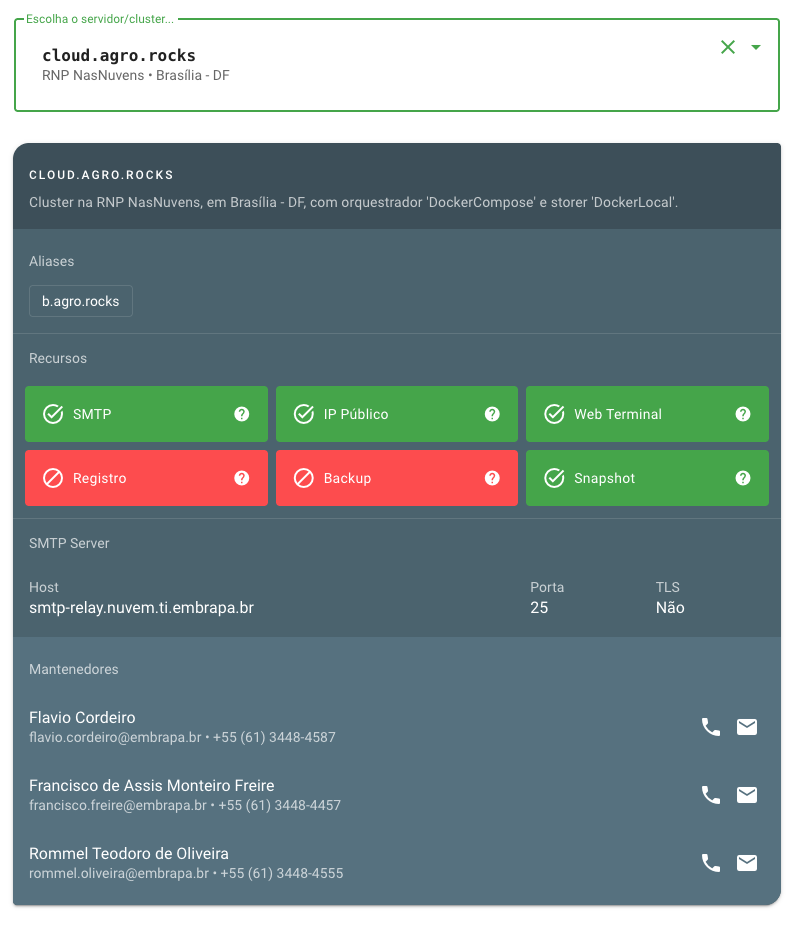
O atributo resources irá informar ao usuário, no momento da escolha do cluster para deploy da aplicação durante a configuração da build, quais os recursos que estão disponíveis:
-
SMTP: Se há um servidor de SMTP para envio de e-mails associado a este cluster. Se existir, as informações para conexão serão exibidas ao usuário.
-
IP Público: Se o cluster possui um IP Público. Caso possua, é possível o acesso direto às portas provisionadas para os serviços e, com isso, disponibilizar nele serviços não-HTTP, tal como brokers IoT (MQTT, CoAP, AMQP, XMPP, etc). Caso não possua, todas as aplicações neste cluster estarão acessíveis apenas pelo provisionamento HTTPS que o Embrapa I/O faz (roteando o tráfego pelo balanceador de carga via virtual proxy).
-
Web Terminal: Se o cluster suporta a funcionalidade de Web Terminal.
-
Registro: Se o cluster possui registro local para as imagens dos containers.
-
Backup: Se existe neste cluster processo automatizado e individualizado de backup das aplicações.
-
Snapshot: Se é realizado o backup do tipo snapshot na(s) VM(s) do cluster em questão.
Atenção! Repare que o recursos de backup difere do recurso de snapshot. No primeiro, caso esteja disponível, será possível a recuperação de aplicações específicas, de forma individualizada. No segundo, o restore da VM é realizada em caso de um problema crítico, que afete o cluster como um todo.
Caso o atributo disabled esteja setado como true, o cluster não aceitará novos deploys naquele cluster para aquele estágio específico (ou seja, ele pode estar disabled para o estágio release, mas não para alpha e beta), porém as builds já instanciadas continuarão sendo geridas normalmente (inclusive recebendo deploys de novas tags). Por fim, é possível estabelecer grupos diferentes de mantenedores para o cluster em cada estágio.